
1-click AWS Deployment 1-click Azure Deployment 1-click Google Deployment
Overview
SQL Server 2014 brings revolutionary performance to quicken business and empower new, transformational scenarios that make you more viable. Microsoft offers complete in-memory technologies for OLTP, data warehousing, and analytics built directly into SQL Server, so there is no need to buy specialized hardware, expensive add-ons or learn new skills to speed your transactions, your queries and your understandings.SQL Server 2014 also provides new hybrid solutions for cloud backup and disaster recovery as well as takes advantage of new capabilities in Windows Server 2012 R2 to provide enterprise-class availability and scalability with predictable performance and reduced infrastructure costs. SQL Server 2014 also continues to offer industry leading business intelligence capabilities and integration with familiar tools like Excel for faster insights on your data. SQL Server 2014 is the next generation of Microsoft’s information platform, with new features that deliver faster performance, expand capabilities in the cloud, and provide powerful business insights. In this book, we explain how SQL Server 2014 incorporates in-memory technology to boost performance in online transactional processing (OLTP) and data-warehouse solutions. We also describe how it eases the transition from on-premises solutions to the cloud with added support for hybrid environments. SQL Server 2014 continues to include components that support analysis, although no major new features for business intelligence were included in this release. However, several advances of note have been made in related technologies such as Microsoft Excel 2013, Power BI for Office 365, HDInsight, and PolyBase.
SQL Server 2014 is very much the familiar SQL Server. It uses the same familiar management tools, the same T-SQL language, and the same APIs that connect it to your applications. That means you should be able to upgrade existing databases in place, to take advantage of its performance and scaling advances. Also, Microsoft has been looking at the ways we use data in modern applications, and added new features that should intensely improve performance and that also bring on-premises databases and the cloud closer together.
SQL Server 2014 connection with Azure:
Azure cloud platform mixes its own SQL Azure database service with SQL Server running on virtual machines as part of its IaaS (Infrastructure-as-a-Service) offering. Although SQL Server 2014 is an awesome application, rather than a service, it’s been designed to take advantage of the cloud, using Azure’s storage and IaaS capabilities to give businesses of all sizes access to cloud-hosted disaster recovery. Large databases can mean expensive, and often slow, backups. Using Azure as a subscription-based backup, there’s no need for CAPEX, and you can use your existing backup techniques — just with Azure as a target. It’s arguably more secure than a traditional backup: Azure holds three copies of your data, so it’s always available. Getting started can take time, so Azure offers the option of letting you make your initial backup on a local disk, that’s then mailed to Microsoft and stored in Azure, ready for the rest of your backups over the wire. Backups can be encrypted, and there’s even support for older versions of SQL Server. Managed backup tools automate the process. All you need to do is define the Azure account you’re using and a retention period. SQL Server will then backup logs every 5MB, every day, or 1GB. If you accidently delete a log backup, the system will detect that you no longer have a consistent backup chain, and will take a full backup. Azure and SQL Server can also be used as a disaster recovery (DR) solution, with an Azure IaaS SQL Server designated as an always-on replica. As soon as an on-premises server fails, you’re switched to a cloud-hosted SQL Server instance preloaded with the last backup. It’s not the cheapest approach, but it does mean you don’t need to invest in running your own DR site. You can use any Azure region, and all you need to pay for is the IaaS VM and the storage you need. The backup tools validate the environment, and handle failures.
One cheaper option is to use SQL Server’s Azure cloud backup as the basis of a cold-start DR service. Hosting a suspended SQL Server instance on Azure IaaS (which only costs you when your server runs), you can use your cloud backup data to update the databases associated with your cloud DR server, bringing you back online after a failure. It’s not as fast as a failover onto an always-running DR server, but it’s an economical approach that will work well for smaller businesses.
With hybrid cloud scenarios in mind, there’s also tooling that will migrate a SQL Server database from an on-premises server to a virtual machine running on Azure. It’s not just for SQL Server 2014, either, as the wizard will migrate SQL Server 2008, 2008 R2 and 2012, with support for VMs running SQL Server 2012 and 2014. It’s an approach that makes it easier to handle database migrations, or to use Azure as a development platform for new applications — or, of course, to move from on-premises to cloud.
Deploying SQL Server 2014 in Azure is abridged by Microsoft providing VM images with SQL Server already installed. We just have to pick the image we want, deploy it, and we are done. Once it’s instantiated you can open SQL Server 2014’s Management Studio, and use the Deploy Database to Windows Azure VM option to launch the wizard. Connect to the remote server, sign in to Azure, publish to a database in your VM, and (once the data has uploaded) away you go.
SQL Server 2014 provides a new in-memory capability for tables that can fit entirely in memory Whilst small tables may be entirely resident in memory in all versions of SQL Server, they also may reside on disk, so work is involved in reserving RAM, writing evicted pages to disk, loading new pages from disk, locking the pages in RAM while they are being operated on, and many other tasks. By treating a table as guaranteed to be entirely resident in memory much of the ‘plumbing’ of disk-based databases can be avoided. For disk-based SQL Server applications, it also provides the SSD Buffer Pool Extension, which can improve performance by cache between RAM and spinning media.SQL Server 2014 also enhances the Always On (HADR) solution by increasing the readable secondaries count and sustaining read operations upon secondary-primary disconnections, and it provides new hybrid disaster recovery and backup solutions with Microsoft Azure, enabling customers to use existing skills with the on-premises version of SQL Server to take advantage of Microsoft’s global datacenters. In addition, it takes advantage of new Windows Server 2012 and Windows Server 2012 R2 capabilities for database application scalability in a physical or virtual environment.Microsoft delivers three versions of SQL Server 2014 for downloading: the one that runs on Microsoft Azure, the SQL Server 2014 CAB, and SQL Server 2014 ISO. SQL Server 2014 is the last version available on x86/IA32 architecture.
SQL Server 2014 In-Memory OLTP Architecture and Data Storage
- Built-in to SQL Server for a hybrid and integrated experience – The idea behind this principal was to integrate the In-memory OLTP engine in the main SQL Server engine. Users will have an hybrid architecture combining the best of both of architectures allowing users to create both traditional disk based tables as well as the newly introduced memory optimized tables in the same database. This integrated approach gives users the same manageability, administration and development experience. Further it allows for the writing of integrated queries combining both disk based tables as well as memory optimized tables. Finally the integration allows users to have integrated high availability (i.e. AlwaysOn) and backup\restore options.
- Optimize for main memory data access – As we are witnessing the steady decline in memory prices, the second principal was to leverage large amounts of memory as much as possible. By storing data and index structure of the memory optimized tables in memory only, the memory optimized tables don’t use the buffer pool or B-tree structure for indexes. This new architecture uses stream based storage for data persistence on disk.
- Accelerate business logic processing – The idea behind this principal is to compile T-SQL to machine\native code via a C code generator and use aggressive optimization during compile time with the Microsoft’s Visual C/C++ compiler. Once compiled, invoking a procedure is just a DDL entry-point and it achieves much of the performance by executing compiled stored procedures. Remember, the cost of interpreted T-SQL stored procedures and their query plans is also quite significant. For an OLTP workload the primary goal is to support efficient execution of compile-once-and-execute-many-times workloads as opposed to optimizing the execution of ad hoc queries.
- Provide frictionless scale-up – The idea behind this principal was to provide high concurrency to support a multi-user environment without blocking (remember blocking implies context switches which are very expensive) and better utilize the multi-core processors. Memory optimized tables use multiversion optimistic concurrency control with full ACID support and it does not require a lock manager because it uses a lock\latch\spinlock free algorithm. This principle is based around optimistic concurrency control where the engine is optimized around transactions that don’t conflict with each other. Multi-versioning eliminates many potential conflicts between transactions and the rest (and very few of them) are handled by rolling back one of the conflicting transactions rather than blocking.
If you look at the below architecture, you will notice there are certain areas which remain same for accessing memory optimized tables vs. disk based tables. For example the client connects to the TDS handler and Session Management module irrespective of whether he\she wants to access a memory optimized table or disk based table. The same is true when call a natively compiled stored procedures or interpreted T-SQL stored procedure. And then there are certain changes about how memory optimized tables are created, stored, managed and accessed. Further, Query Interop allows interpreted T-SQL queries and stored procedures to access memory optimized tables.
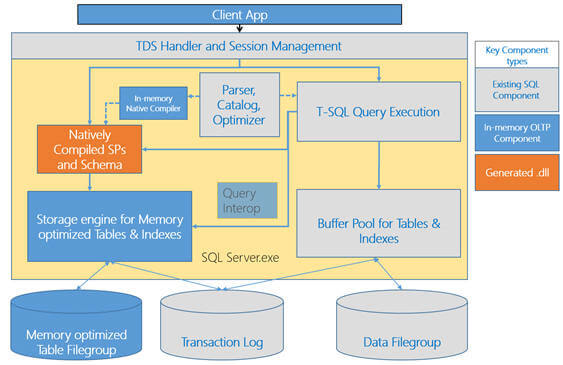
The In-memory native compiler takes an abstract tree representation of a T-SQL stored procedure defined as a native stored procedure. This representation includes the queries within the stored procedure, in addition to the table and index metadata then compiles the procedure into native\machine code. This code is designed to execute against tables and indexes managed by the storage engine for memory optimized tables.
The In-memory storage engine manages user data and indexes of the memory optimized tables. It provides transactional operations on tables of records, hash and range indexes on the tables, and base mechanisms for storage, check pointing, recovery and high-availability. For a durable (more on durability in next part of this tip series) table, it writes data to filestream based filegroup on disk so that it can recover in case a server crashes. It also logs its updates to the SQL Server database transaction log along with the log records for disk based tables. It uses SQL Server file streams for storing checkpoint files which are used, to recover memory optimized tables automatically when a database is recovered or restored.
Other than these items, as I said In-memory OLTP is fully integrated into the existing SQL Server database engine. Hekaton leverages a number of services already available in SQL Server, for example:
- Meta data about memory optimized tables are stored in the SQL Server catalogs
- A transaction can access and update data in both memory optimized and disk based tables
- If you have setup a AlwaysOn availability group then memory optimized tables will fail over in the same manner as disk based tables
SQL Server 2014 Data Storage
Memory optimized tables have a completely new row format for storage of row data in memory and the structure of the row is optimized for memory residency and access. Unlike, disk based tables for which data gets stored in the data or index pages, memory optimized tables do not have any page containers. As I said before, In-memory OLTP uses multi-version for data changes, which means the payload does not get updated in place, but rather rows are versioned on each data change.

With Hekaton, every row has a begin timestamp and an end timestamp, which determines the row’s version, validity and visibility. The begin timestamp indicates the transaction that inserted the row whereas the end timestamp indicates the transaction which actually deleted the row. A value of infinity for the end timestamp indicates the row has not been deleted and it is the latest version. Updating a row is a combination of deleting an existing record and inserting a new record. For a read operation – only record versions whose valid time overlaps the read time will be visible to the read, all other versions are ignored. Different version of the record will always have non-overlapping time validity and hence at most only one version of the record will be visible to the read operation. Having said that, the begin timestamp and end timestamp values determine, which other transactions will be able to see this row.
Keep in mind, all the memory optimized tables are fully stored in memory and hence you need to make sure you have enough memory available. One recommendation is 2 times the data size. You will also need to verify you have enough memory for buffer pools for your disk based tables. If you don’t have enough memory then your transactions will start failing or if you are recovering\restoring, this operation will fail if you don’t have enough space to accommodate all the data of the memory optimized tables. Please note, you don’t need physical memory to accommodate the entire database, which could be in terabytes, but you need to accommodate all your memory optimized tables, which should not be more than 256 GB in size.
Preparation
For local installations, you must run Setup as an administrator. If you install SQL Server from a remote share, you must use a domain account that has read and execute permissions on the remote share.
It is best to install the server from a DVD or from a mounted ISO file which behaves as a CD/DVD. In this case, once you double click the DISK icon the autorun.inf file is used by the AutoRun and AutoPlay components of Microsoft Windows operating systems. This will start the installation using the configuration in the autorun.inf file. If AutoRun is disabled on your server, you may double click setup.exe to start the installation. To install from a network share, locate the proper folder on the share, and then double-click setup.exe.
Installation, Step By Step
1. Upon starting the installation, you will get this window:
2. Choose the Installation section in order to start the installation:
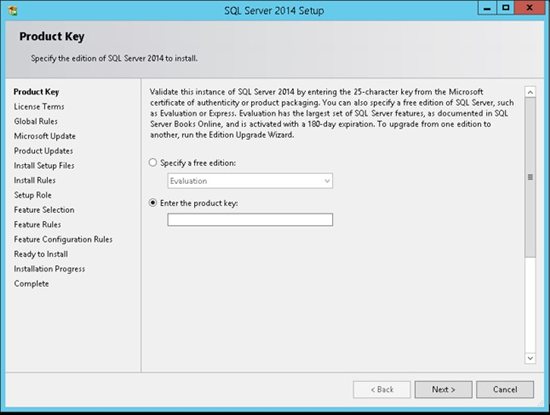
3. Enter the product key and click Next:
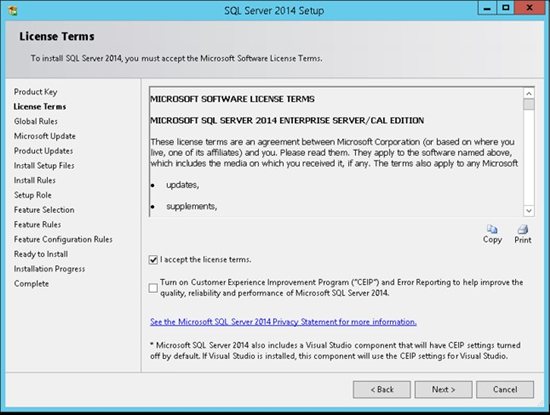
4. You have to accept the license term in order to continue.
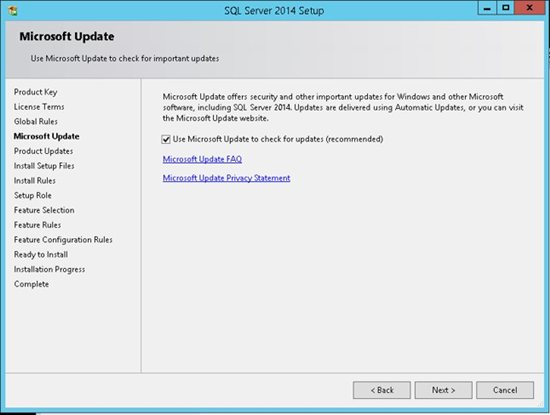
5. Mark the check box in order to use Microsoft Update to check for an update after you finished the installation, and then click Next.
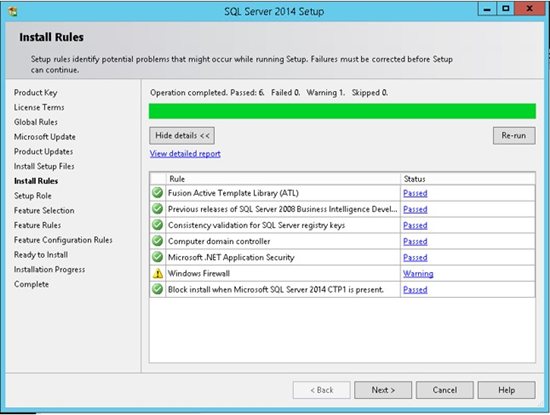
6. The SQL Server installation program checks your machine to make sure it meets the hardware and software requirements to install SQL Server. If you get any Errors in the results, please use the link in the error message to get more information.
Do not move to the next step if you get any errors in this report!
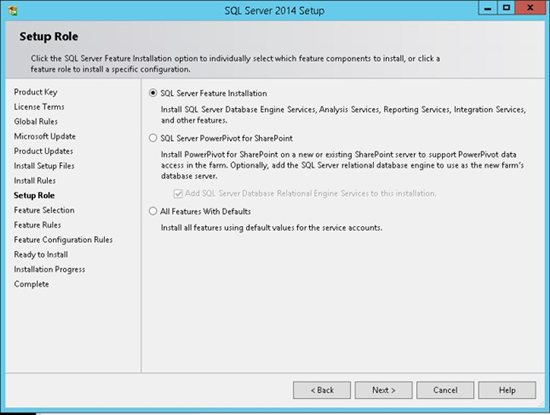
7. Choose the first option in order to install SQL Server, and then select which features to install. We are going to choose our features manually in the next step. Click Next to continue:
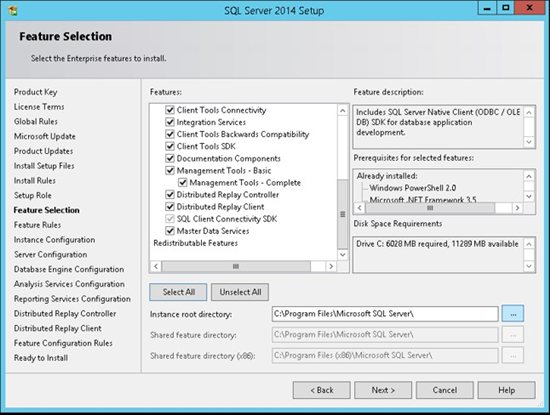
8. In this step, you can choose what features to install. It is highly recommend NOT to choose all the features on a production server if you don’t need them. Choose only the features that you need or might need. Conversely you might want to select all using a development server in order to give you more flexibility in your development environment. Once you choose to use another feature you will be able to add it in production later on.
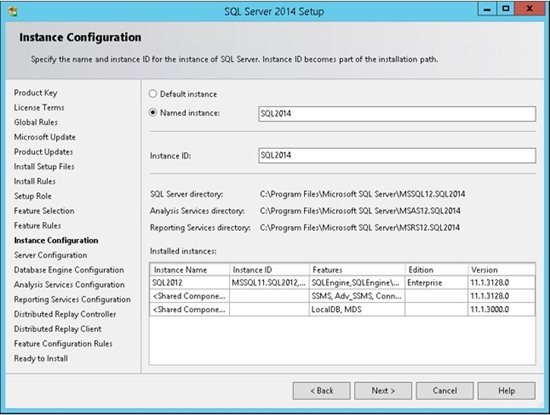
9. SQL Server allows you to install multiple instances of the same version or different versions of the server. Make sure you choose a name that will help you in the future to recognize the instance which you are working with. Theoretically you can use any instance name that you want.
* Remember the name of the instance!
You will need to use this name every time that you want to connect to the server.
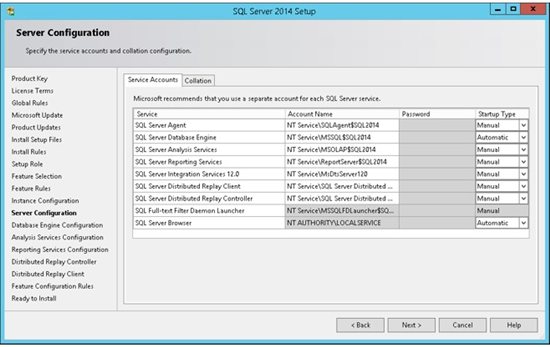
10. Security is important for every product and every business. By following simple best practices, you can avoid many security vulnerabilities. SQL Server works as a group of services in the background. In this step you can select the service accounts for the SQL Server actions. Each service in SQL Server represents a process or a set of processes to manage authentication of SQL Server operations with Windows. Each service can be configured to use its own service account.
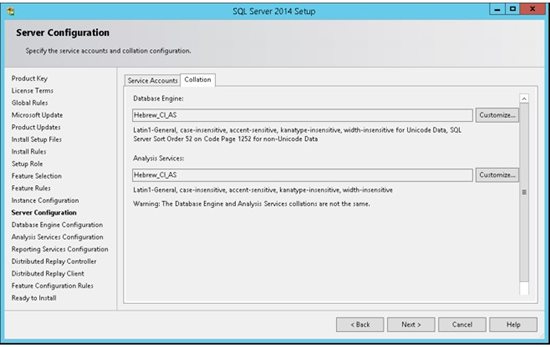
11. SQL Server supports several collations. A collation encodes the rules governing the proper use of characters for either a language, such as Hebrew or Polish, or an alphabet, such as Latin1_General (the Latin alphabet used by western European languages). Typically, you should choose a SQL Server collation that supports most languages commonly used by users at your organization. Select the collation and press next.
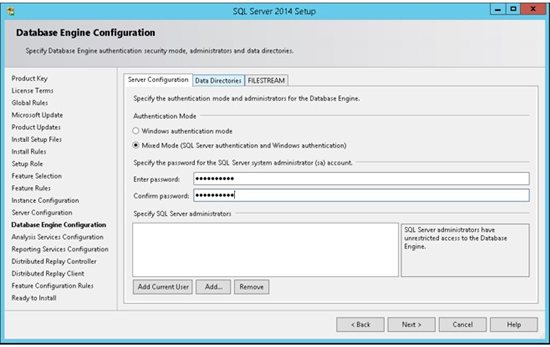
12. SQL Server can operate in one of two security (authentication) modes: (a) Windows Authentication mode which allowed a user to connect through an operating system user account. or (b) Mixed Mode which allowed users to connect to an instance of SQL Server using either Windows Authentication or SQL Server Authentication.
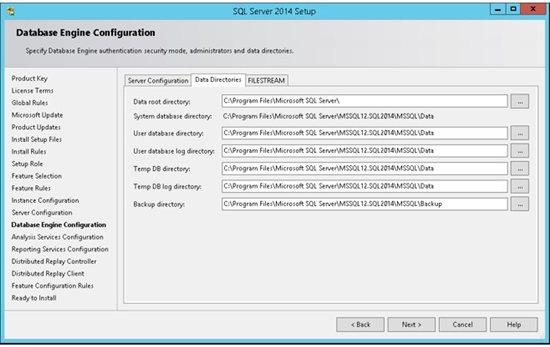
13. By default SQL Server uses the system operation disk Thus it is highly recommended to use the best practice according to your specific system and usage. Separating the LOG files from the data files can improve performance significantly. The system database tempDB is used extensively by SQL Server. This database is rebuilt each time the server is restarted. (See this article for details about TempDB ) It is highly recommended to use a fast disk for this database. It is best practice to separate data, transaction logs, and tempdb for environments where you can guarantee that separation. There are important points to considerate and this article is not covering them at the moment. For small systems you can use the default configuration and later on change as needed.
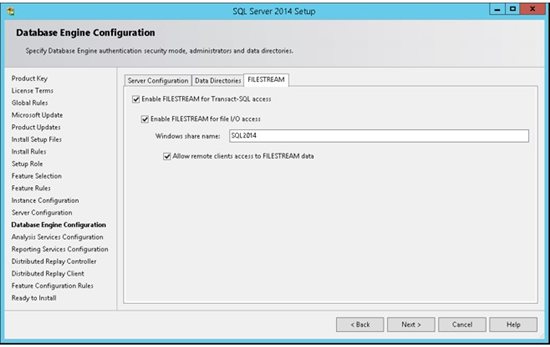
14. FILESTREAM enables SQL Server-based applications to store unstructured data, such as documents and images, on the file system. FILESTREAM integrates the SQL Server Database Engine with an NTFS file system by storing varbinary(max) binary large object (BLOB) data as files on the file system.
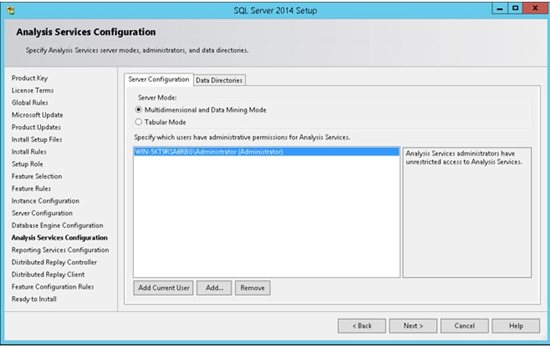
15. An instance of Analysis Services is a copy of the msmdsrv.exe executable that runs as an operating system service. Each instance is fully independent of other instances on the same server, having its own configuration settings, permissions, ports, startup accounts, file storage, and server mode properties. Server mode is a server property that determines which storage and memory architecture is used for that instance. In this step you can add windows users in order to give them administrative permissions for the Analysis Service. It is highly recommended to add the machine Administrator as well as other users who will need to manage this service. Move to the Data Directories for next step.
16. As mentioned in step 13 the data directories can have significant influence on the server performance. Press Next to continue the installation configuration.
17. Choose if you want to install and configure the Reporting Service or just Install, which mean you will need to configure it later on.
18. Before you install and use the Microsoft SQL Server Distributed Replay feature, you should review the important security information .
19. When installing the Microsoft SQL Server Distributed Replay features, consider the following:
- You can install the administration tool on the same computer as the Distributed Replay controller, or on different computers.
- There can only be one controller in each Distributed Replay environment.
- You can install the client service on up to 16 (physical or virtual) computers.
- Only one instance of the client service can be installed on the Distributed Replay controller computer. If your Distributed Replay environment will have more than one client, we do not recommend installing the client service on the same computer as the controller. Doing so may decrease the overall speed of the distributed replay.
- For performance testing scenarios, we do not recommend installing the administration tool, Distributed Replay controller service, or client service on the target instance of SQL Server. Installing all of these features on the target server should be limited to functional testing for application compatibility.
- After installation, the controller service, SQL Server Distributed Replay controller, must be running before you start the Distributed Replay client service on the clients.
- Make sure that the computers that you want to use meet the requirements that are described in the topic Distributed Replay Requirements.
- Before you begin this procedure, you create the domain user accounts that the controller and client services will run under. We recommend that these accounts are not members of the Windows Administrators group. For more information, see the User and Service Accounts section in the Distributed Replay Security topic.
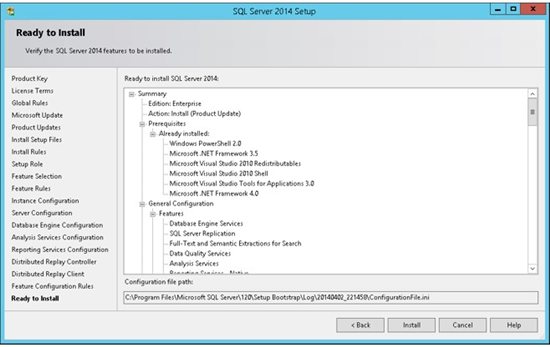
20. The SQL Server Installation program will show us a report of all our configuration (steps 1-19). Once you select Next, the installation will start.
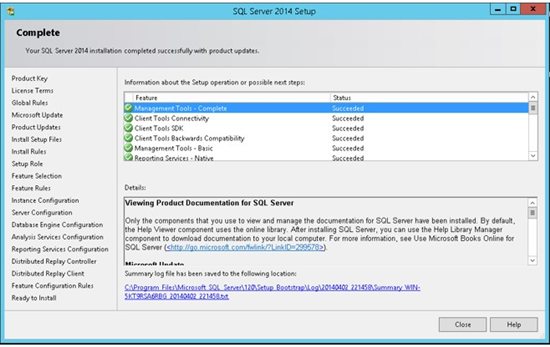
If everything went well and you should get a final report which indicates the successful completion of each installed service. You are now ready to connect to the server .
Connecting to the Server
Open the new SSMS application which we have just installed (in step 8 we choose which features to install, If you have chosen Management Tools it includes the SQL Server Management Studio).
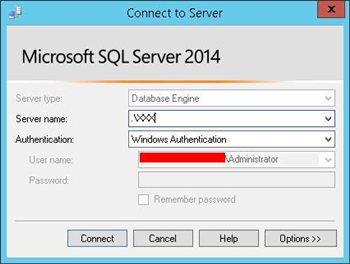
During step 9 we choose an instance name for our new installation. We told you to Remember the name of the instance. Now it is time to use it.
–SQL Server Enterprise 2014 is the whole kit and caboodle. Every feature of SQL Server is included in the enterprise edition. Some features of SQL server 2014 are only available in enterprise edition, such as always on instance clustering and always on availability groups.
SQL Server 2014 Enterprise edition on cloud is designed for today’s most demanding enterprise applications with built in mission-critical capabilities to ensure applications and data are up and available, scalable and secure.
Cognosys Provides Hardened images of SQL Server Enterprise 2014 on the cloud ( SQL Server Enterprise 2014 on AWS marketplace, SQL Server Enterprise 2014 on Azure and SQL Server Enterprise 2014 on Google Cloud Platform).
Click on the respective cloud provider tab for technical information.
Deploy SQL Server 2014 Enterprise securely on cloud i.e. AWS marketplace, Azure and Google Cloud Platform (GCP)
SQL Server 2014 Enterprise Edition with IIS On Win 2012 R2
SQL Server Enterprise 2014 on cloud for AWS
Features
Microsoft has introduced some substantial enrichments in SQL Server 2014, specifically with In-Memory OLTP. And we can assume after such a short release cycle, not every subsystem has been updated; there are no major changes to SQL Server Integration Services (SSIS), SQL Server Replication Services, or SQL Server Reporting Services (SSRS). However, there are profusely significant enhancements and some of them are explained below:
10 new features in SQL Server 2014
1. In-Memory OLTP Engine
SQL Server 2014 enables memory optimization of selected tables and stored procedures. The In-Memory OLTP engine is designed for high concurrency and uses a new optimistic concurrency control mechanism to eliminate locking delays. Microsoft states that customers can expect performance to be up to 20 times better than with SQL Server 2012 when using this new feature.
2. AlwaysOn Enhancements
Microsoft has enhanced AlwaysOn integration by intensifying the maximum number of secondary replicas from four to eight. Readable secondary replicas are now also available for read workloads, even when the primary replica is unavailable. In addition, SQL Server 2014 provides the new Add Azure Replica Wizard, which helps you create asynchronous secondary replicas in Windows Azure.
3. Buffer Pool Extension
SQL Server 2014 provides a new solid-state disk (SSD) integration capability that lets you use SSDs to expand the SQL Server 2014 Buffer Pool as nonvolatile RAM (NvRAM). With the new Buffer Pool Extensions feature, you can use SSD drives to expand the buffer pool in systems that have maxed out their memory. Buffer Pool Extensions can provide performance gains for read-heavy OLTP workloads.
4 .Updateable Columnstore Indexes
When Microsoft introduced the columnstore index in SQL Server 2012, it provided improved performance for data warehousing queries. For some queries, the columnstore indexes provided a tenfold performance improvement. However, to utilize the columnstore index, the underlying table had to be read-only. SQL Server 2014 eliminates this restriction with the new updateable Columnstore Index. The SQL Server 2014 Columnstore Index must use all the columns in the table and can’t be combined with other indexes.
5.Storage I/O control
The Resource Governor lets you limit the amount of CPU and memory that a given workload can consume. SQL Server 2014 extends the reach of the Resource Governor to manage storage I/O usage as well. The SQL Server 2014 Resource Governor can limit the physical I/Os issued for user threads in a given resource pool.
6. Power View for Multidimensional Models
Power View used to be limited to tabular data. However, with SQL Server 2014, Power View can now be used with multidimensional models (OLAP cubes) and can create a variety of data visualizations including tables, matrices, bubble charts, and geographical maps. Power View multidimensional models also support queries using Data Analysis Expressions (DAX).
7. Power BI for Office 365 Integration
Power BI for Office 365 is a cloud-based business intelligence (BI) solution that provides data navigation and visualization capabilities. Power BI for Office 365 includes Power Query (formerly code-named Data Explorer), Power Map (formerly code-named GeoFlow), Power Pivot, and Power View. You can learn more about Power BI at Microsoft’s Power BI for Office 365 site.
8. SQL Server Data Tools for Business Intelligence
The new SQL Server Data Tools for BI (SSDT-BI) is used to create SQL Server Analysis Services (SSAS) models, SSRS reports, and SSIS packages. The new SSDT-BI supports SSAS and SSRS for SQL Server 2014 and earlier, but SSIS projects are limited to SQL Server 2014. In the pre-release version of SQL Server 2014, SQL Server Setup doesn’t install SSDT-BI. So we can separately download SSDT-BI separately from the Microsoft Download Center.
9. Backup Encryption
One welcome addition to SQL Server 2014 is the ability to encrypt database backups for at-rest data protection. SQL Server 2014 supports several encryption algorithms, including Advanced Encryption Standard (AES) 128, AES 192, AES 256, and Triple DES. You must use a certificate or an asymmetric key to perform encryption for SQL Server 2014 backups.
10. SQL Server Managed Backup to Windows Azure
SQL Server 2014’s innate backup supports Windows Azure integration. However no one wants to depend on an Internet connection to restore my backups, on-premises SQL Server 2014 and Windows Azure virtual machine (VM) instances support backing up to Windows Azure storage. The Windows Azure backup integration is also fully built into SQL Server Management Studio (SSMS).
SQL Server 2014 (SP2) Includes the following improvements:
Performance and Scalability Improvements
- Automatic Soft NUMA partitioning:With SQL Server 2014 SP2, Automatic Soft NUMA is enabled when Trace Flag 8079 is turned on during instance startup. When Trace Flag 8079 is enabled during startup, SQL Server 2014 SP2 will interrogate the hardware layout and automatically configure Soft NUMA on systems reporting 8 or more CPUs per NUMA node. The automatic, soft NUMA behavior is Hyperthread (HT/logical processor) aware. The partitioning and creation of additional nodes scales background processing by increasing the number of listeners, scaling, and network and encryption capabilities. We recommend that you first test the performance workload with Auto-Soft NUMA, before tuning it in production.
- Dynamic Memory Object Scaling:SQL Server 2014 SP2 dynamically partitions memory objects based on number of nodes and cores to scale on modern hardware. The goal of dynamic promotion is to automatically partition a thread safe memory object (CMEMTHREAD) if it becomes a bottleneck. Non-partitioned memory objects can be dynamically partitioned by node (number of partitions equals number of NUMA nodes). Memory objects partitioned by node can by further partitioned by CPU (number of partitions equals number of CPUs.
- MAXDOP hint for DBCC CHECK* commands You can now run DBCC CHECKDB with a MAXDOP setting other than the sp_configure value. If MAXDOP exceeds the value configured with Resource Governor, the Database Engine uses the Resource Governor MAXDOP value, described in ALTER WORKLOAD GROUP (Transact-SQL). All semantic rules used with the max degree of parallelism configuration option are applicable when you use the MAXDOP query hint.
- Enable >8 TB for Buffer Pool:SQL Server 2014 SP2 enables 128 TB of virtual address space for buffer pool usage. This improvement enables SQL Server Buffer Pool to scale beyond 8 TB on modern hardware.
- SOS_RWLock spinlock Improvement:The SOS_RWLock is a synchronization primitive used in various places throughout the SQL Server code base. As the name implies, the code can have multiple shared (readers) or single (writer) ownership. This improvement removes the need for spinlock for SOS_RWLock and instead uses lock-free techniques similar to in-memory OLTP. With this change, many threads can read a data structure protected by SOS_RWLock in parallel, without blocking each other. This parallelization provides increased scalability. Prior to this change, the spinlock implementation allowed only one thread to acquire the SOS_RWLock at a time, even to read a data structure
- Spatial Native Implementation:Significant improvement in spatial query performance is introduced in SQL Server 2014 SP2 through native implementation..
Supportability and Diagnostics Improvements
- Database Cloning:Clone database is a new DBCC command that enhances troubleshooting existing production databases by cloning the schema and metadata without the data. The clone is created with the command DBCC clonedatabase(‘source_database_name’, ‘clone_database_name’). Note: Cloned databases should not be used in production environments. Use the following command determine if a database has been generated from a cloned database: select DATABASEPROPERTYEX(‘clonedb’, ‘isClone’). The return value of 1 indicates the database is created from clonedatabase while 0 indicates it is not a clone.
- Tempdb supportability:A new error log message that indicates at start-up both the number of tempdb files, and the size and autogrowth of tempdb data files.
- Database Instant File Initialization Logging:A new error log message that indicates on server startup, the status of Database Instant File Initialization (enabled/disabled).
- Module names in callstack:The extended event (XEvent) callstack now includes modules names plus offset, instead of absolute addresses.
- New DMF for incremental statistics:This improvement addresses connect feedback (797156) to enable tracking the incremental statistics at the partition level. A new DMF sys.dm_db_incremental_stats_properties is introduced to expose information per-partition for incremental stats.
- Index Usage DMV behavior updated:This improvement addresses connect feedback (739566) from customers where rebuilding an index will not clear any existing row entry from sys.dm_db_index_usage_stats for that index. The behavior will now be the same as in SQL 2008 and SQL Server 2016.
- Improved correlation between diagnostics XE and DMVs:This improvement addresses connect feedback (1934583). Query_hash and query_plan_hash are used for identifying a query uniquely. DMV defines them as varbinary(8), while XEvent defines them as UINT64. Because SQL server does not have “unsigned bigint”, casting does not always work. This improvement introduces new XEvent action and filter columns. The columns are equivalent to query_hash and query_plan_hash, except they are defined as INT64. The INT64 definition helps to correlate queries between XE and DMVs.
- Support for UTF-8 in BULK INSERT and BCP:This improvement addresses connect feedback (370419). BULK INSERT and BCP can now export or import data that is encoded in the UTF-8 character set.
- Lightweight profiling of query execution per-operator:Showplan provides information on the cost of each operator in the plan. But actual run-time statistics are limited for things such as CPU, I/O Reads, and elapsed time per-thread. SQL Server 2014 SP2 introduces these additional runtime statistics per operator in the Showplan. R2 also introduces an XEvent named query_thread_profile to assist the troubleshooting of query performance
- Change Tracking Cleanup:
- A new stored procedure sp_flush_CT_internal_table_on_demandis introduced to clean the change tracking internal tables on demand.
- AlwaysON Lease Timeout LoggingAdded new logging capability for Lease Timeout messages so that the current time and the expected renewal times are logged. Also a new message was introduced in the SQL Error log regarding the timeouts.
- New DMF for retrieving input buffer in SQL Server:A new DMF for retrieving the input buffer for a session/request (sys.dm_exec_input_buffer) is now available. This DMF is functionally equivalent to DBCC INPUTBUFFE
- Mitigation for underestimated and overestimated memory grant:Added a new query hints for Resource Governor through MIN_GRANT_PERCENT and MAX_GRANT_PERCENT. This new query allows you to leverage these hints while running queries, by capping their memory grants to prevent memory contention.
- Better memory grant and usage diagnostics:A new extended event named query_memory_grant_usage was added to the list of tracing capabilities in SQL Server. This event tracks memory grants requested and granted. This event provides better tracing and analysis capabilities for troubleshooting any query execution issues related to memory grants.
- Query execution diagnostics for tempdb spill:– Hash Warning and Sort Warnings now have additional columns to track physical I/O statistics, memory used, and rows affected. We also introduced a new hash_spill_details extended event. Now you can track more granular information for your hash and sort warnings (KB3107172). This improvement is also now exposed through the XML Query Plans in the form of a new attribute to the SpillToTempDbType complex type (KB3107400). Set statistics ONnow shows sort worktable statistics.
- Improved diagnostics for query execution plans that involve residual predicate pushdown:The actual rows read are now reported in the query execution plans, to help improve query performance troubleshooting. These rows negate the need to capture SET STATISTICS IO separately. These rows also allow you to see information related to a residual predicate push-down in a query plan.
–Major Features of SQL Server Enterprise 2014
1. Cross-Box Scale Limits
2. High Availability
3. Scalability and Performance
4. Security
5. Replication
6. Management Tools
7. RDBMS Manageability
8. Development Tools
9. Programmability
AWS
Installation Instructions For Windows
Installation Instructions for Windows
Step 1) RDP Connection: To connect to the deployed instance, Please follow Instructions to Connect to Windows instance on AWS Cloud
1) Connect to the virtual machine using following RDP credentials:
- Hostname: PublicDNS / IP of machine
- Port : 3389
Username: To connect to the operating system, use RDP and the username is Administrator.
Password: Please Click here to know how to get password
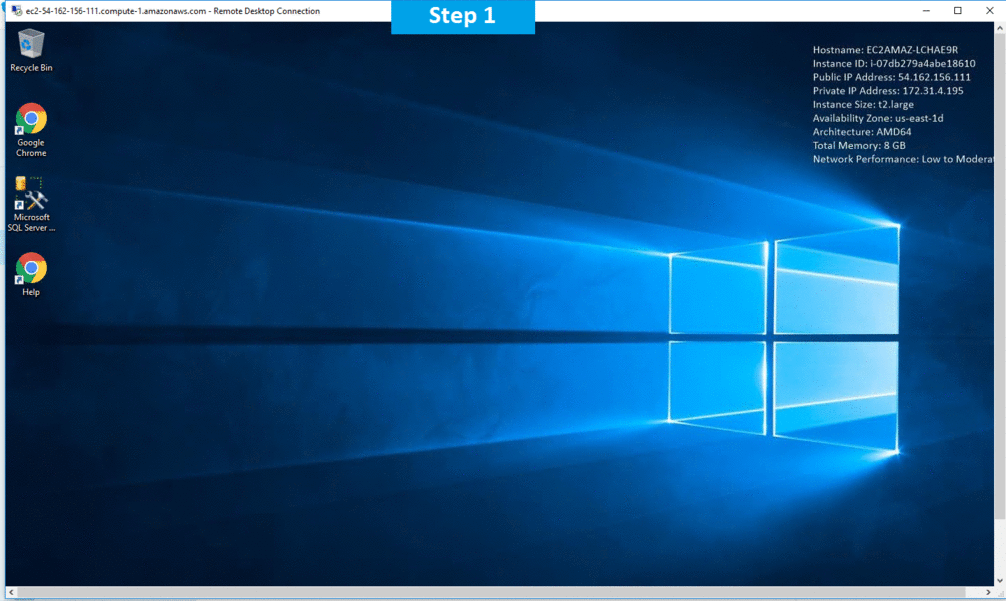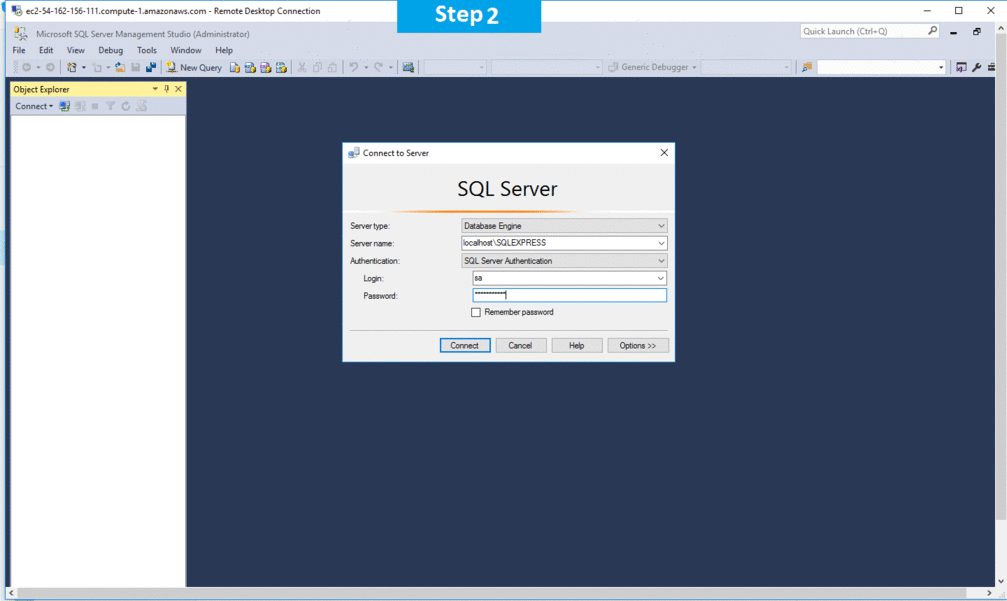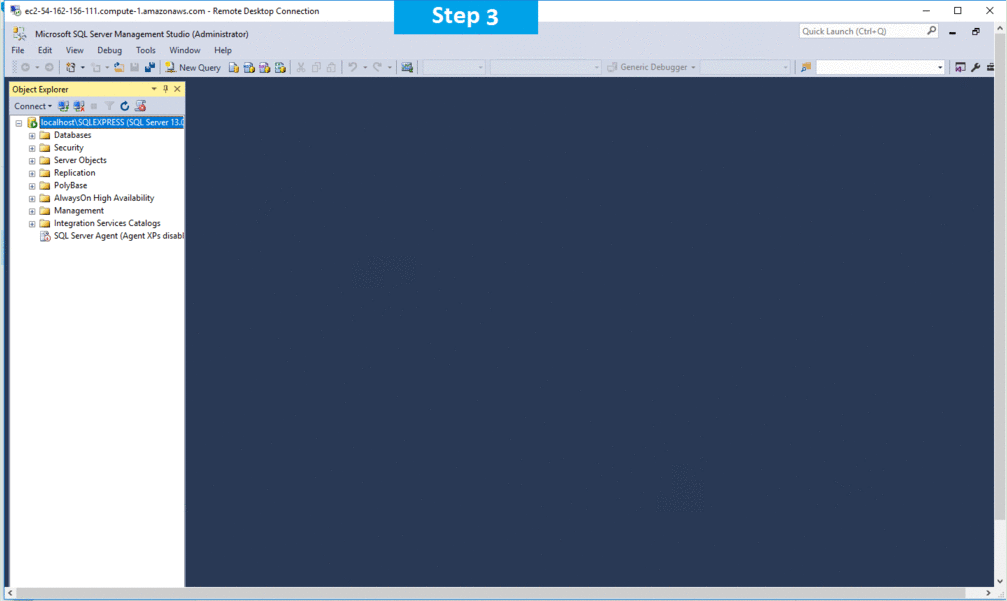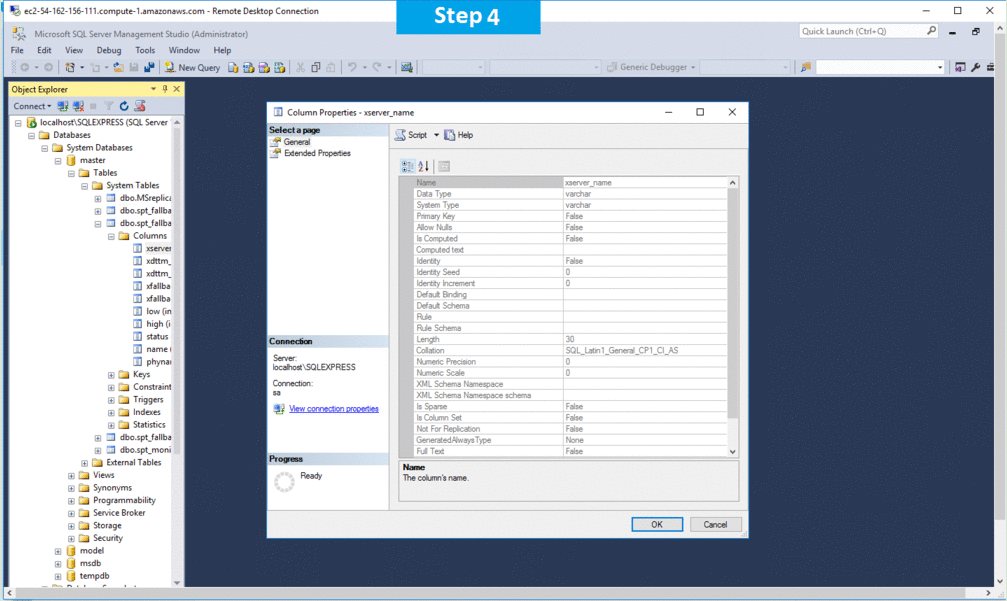
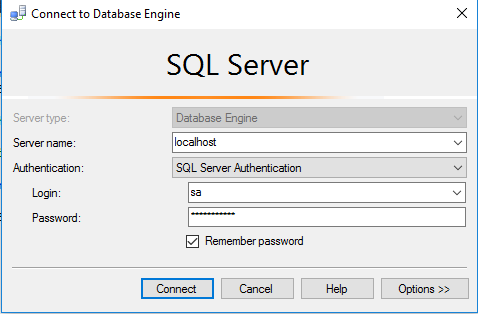
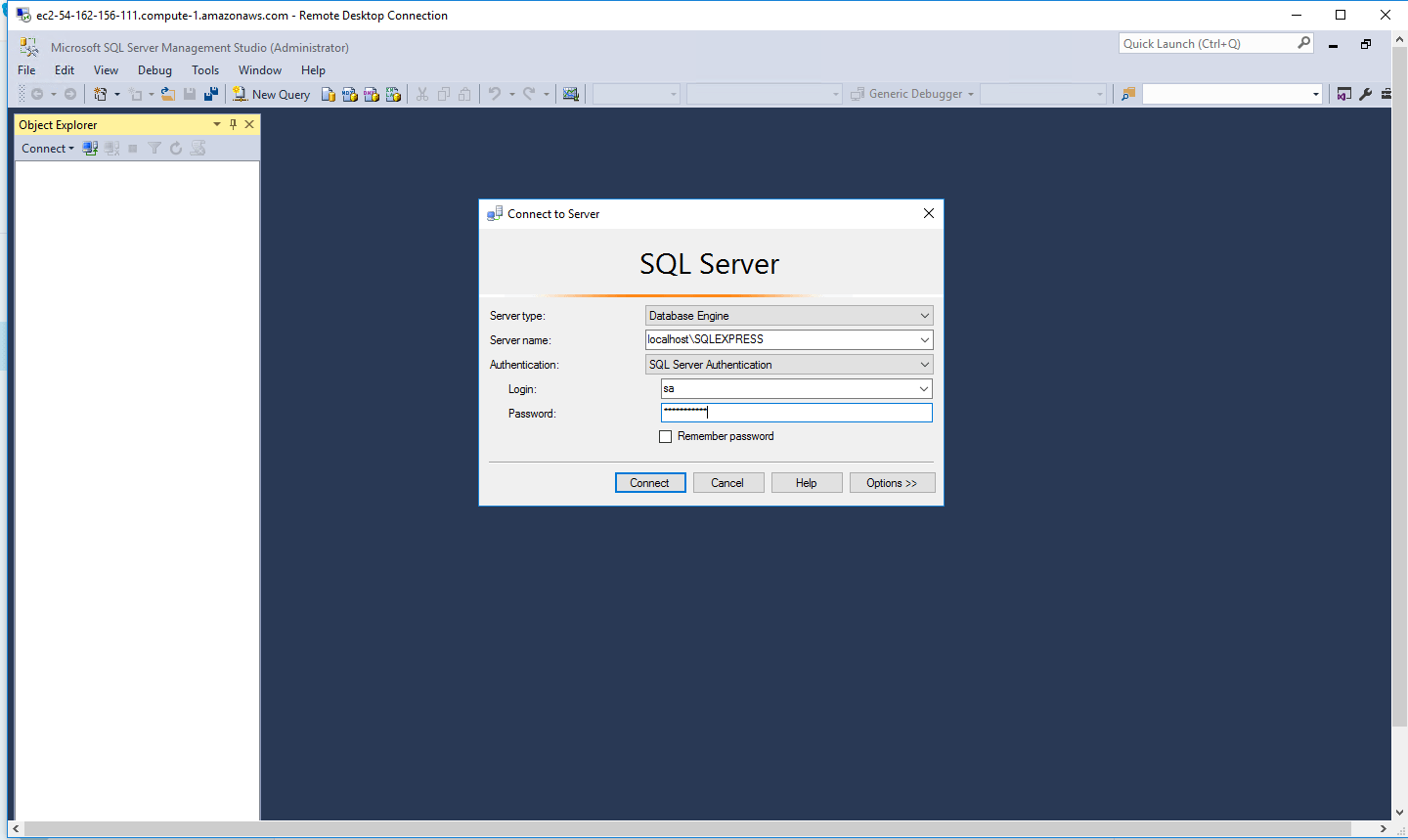
Step 2) SQL Connection: To Connect Microsoft SQL Server Management Studio in Windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio
Step 3) Database Credentials: You can Login by below SQL Database credentials
SQL UserName : sa || Password : Passw@rd123
Note: You can reset ‘sa’ password by using windows authentication to connect to local SQL instance. Please use localhost in the server name when connecting from inside the RDC
Note: Please change the password after the first login.
Step 4) Other Information:
1.Default ports:
- Windows Machines: RDP Port – 3389
- Http: 80
- Https: 443
- SQL Server Port: 1433 this is by default not allowed on the firewall for security.
Configure custom inbound and outbound rules using this link
Installation Step by Step Screenshots
Installation Instructions For Windows
Installation Instructions for Windows
Step 1) VM Creation:
- Click the Launch on Compute Engine button to choose the hardware and network settings.
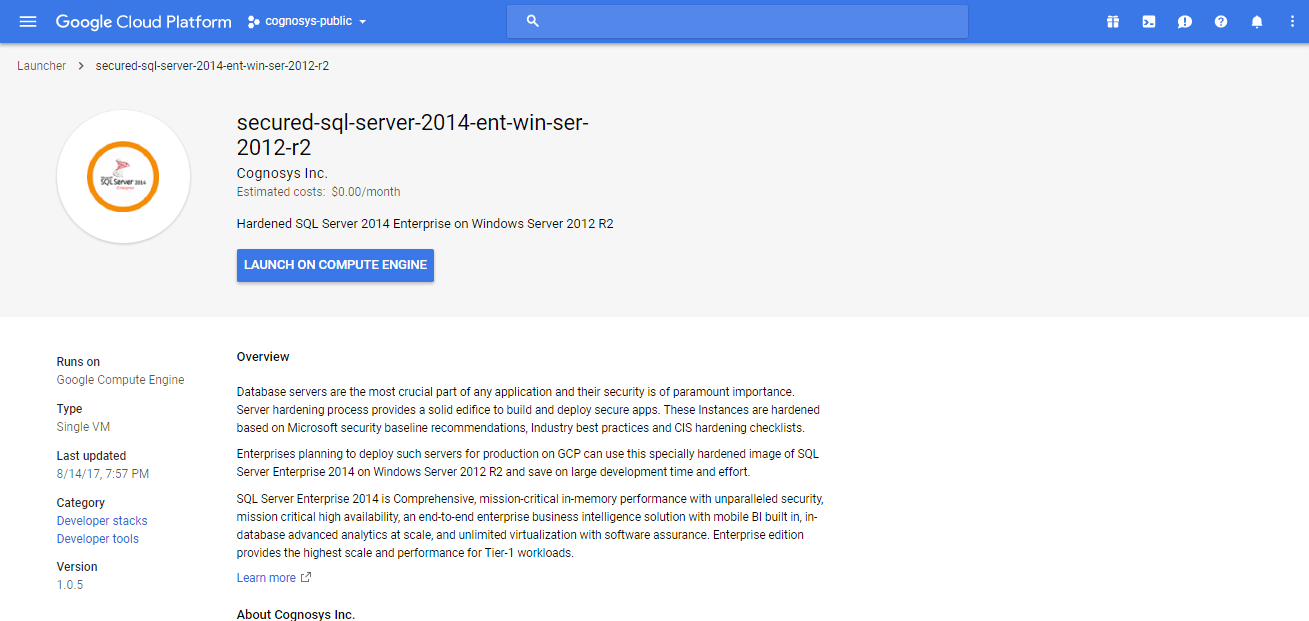
2.You can see at this page, an overview of Cognosys Image as well as estimated cost of running the instance.
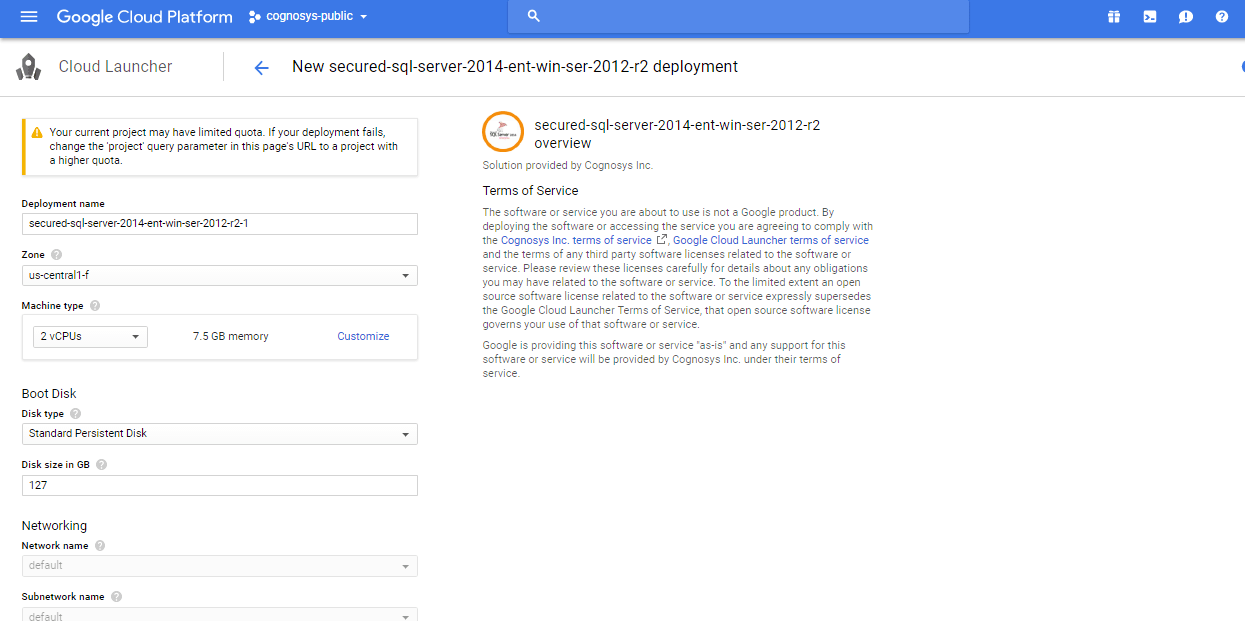
3.In the settings page, you can choose the number of CPUs and amount of RAM, the disk size and type etc.
Step 2) RDP Connection: To connect to the deployed instance, Please follow Instructions to Connect to Windows instance on Google Cloud
Step 3) SQL Connection: To Connect Microsoft SQL Server Management Studio in windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio
Step 4) Database Credentials:
You can Login by below SQL Database credentials
SQL UserName : sa
The below screen appears after successful deployment of the image.
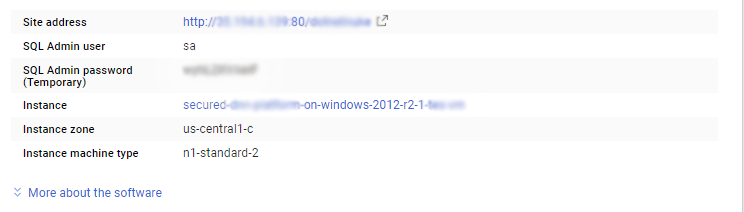
i) Please connect to Remote Desktop as given in step 2
ii) You can use SQL server instance as localhost. The SQL Server instance name to be used is “localhost” Connect to SQL Management Studio with username as sa and password provided in Custom Metadata.
If you have closed the deployment page you can also get the sa password from VM Details “Custom metadata” Section.
Step 5) Other Information:
1.Default ports:
- Windows Machines: RDP Port – 3389
- sql server port :1433: By default, this is blocked on Public interface for security reasons.
Configure custom inbound and outbound rules using this link
