
Azure
Installation Instructions for Windows
Step 1) RDP Connection: To connect to the deployed instance, Please follow Instructions to Connect to Windows instance on Azure Cloud
1) Connect to virtual machine using following RDP credentials:
- Hostname: PublicDNS / IP of machine
- Port : 3389
Username: To connect to the operating system, use RDP and the username is Administrator.
Password : Please Click here to know how to get password .
Step 2) SQL Connection: To Connect Microsoft SQL Server Management Studio in windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio Local SQL Server sa password has been set as Passw@rd123
Step 3) Database Credentials: You can Login by below SQL Database credentials
SQL UserName : sa || Password : Passw@rd123
Note: You can reset ‘sa’ password by using windows authentication to connect to local SQL instance.Please use localhost in the server name when connecting from inside the RDC
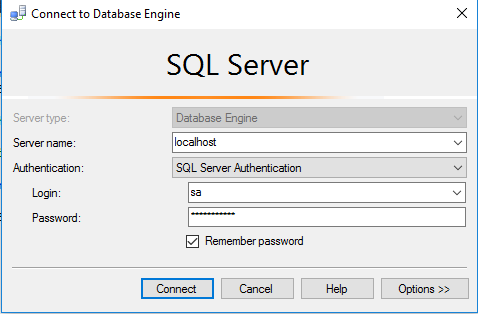
Please change the password after the first login.
Step 4) Other Information:
1.Default ports:
- Windows Machines: RDP Port – 3389
- Http: 80
- Https: 443
- SQL Server Port: 1433 this is by default not allowed on the firewall for security.
2. VSCode and debug utilities have been installed
Installation Instructions for Windows
Step 1) VM Creation:
- Click the Launch on Compute Engine button to choose the hardware and network settings
- You can see at this page, an overview of Cognosys Image as well as estimated cost of running the instance.
- In the settings page, you can choose the number of CPUs and amount of RAM, the disk size and type etc
Step 2) RDP Connection: To initialize local DB server connect to the deployed instance, Please follow Instructions to Connect to Windows instance on Google Cloud
Step 3) SQL Connection: To Connect Microsoft SQL Server Management Studio in windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio
Step 4) Database Credentials: You can Login by below SQL Database credentials
SQL UserName : sa The below screen appears after successful deployment of the image.
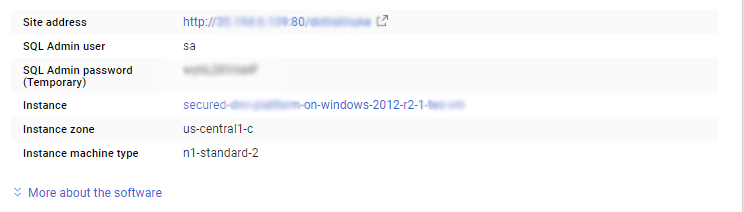 i) Please connect to Remote Desktop as given in step 2 ii) You can use SQL server instance as localhost. The SQL Server instance name to be used is “localhost” Connect to SQL Management Studio with username as sa and password provided in Custom Metadata. If you have closed the deployment page you can also get the sa password from VM Details “Custom metadata” Section.
i) Please connect to Remote Desktop as given in step 2 ii) You can use SQL server instance as localhost. The SQL Server instance name to be used is “localhost” Connect to SQL Management Studio with username as sa and password provided in Custom Metadata. If you have closed the deployment page you can also get the sa password from VM Details “Custom metadata” Section.Step 5 ) Other Information:
1.Default installation path: “C:\Program Files\Microsoft SQL Server ”
2.Default ports:
- Windows Machines: RDP Port – 3389
- SQL server port:1433: By default, this is blocked on the Public interface for security reasons.
Videos
SQL Server 2017
Azure
Installation Instructions for Windows
Step 1) RDP Connection: To connect to the deployed instance, Please follow Instructions to Connect to Windows instance on Azure Cloud
1) Connect to virtual machine using following RDP credentials:
- Hostname: PublicDNS / IP of machine
- Port : 3389
Username: To connect to the operating system, use RDP and the username is Administrator.
Password : Please Click here to know how to get password .
Step 2) SQL Connection: To Connect Microsoft SQL Server Management Studio in windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio Local SQL Server sa password has been set as Passw@rd123
Step 3) Database Credentials: You can Login by below SQL Database credentials
SQL UserName : sa || Password : Passw@rd123
Note: You can reset ‘sa’ password by using windows authentication to connect to local SQL instance.Please use localhost in the server name when connecting from inside the RDC
Please change the password after the first login.
Step 4) Other Information:
1.Default ports:
- Windows Machines: RDP Port – 3389
- Http: 80
- Https: 443
- SQL Server Port: 1433 this is by default not allowed on the firewall for security.
2. VSCode and debug utilities have been installed
Installation Instructions for Windows
Step 1) VM Creation:
- Click the Launch on Compute Engine button to choose the hardware and network settings
- You can see at this page, an overview of Cognosys Image as well as estimated cost of running the instance.
- In the settings page, you can choose the number of CPUs and amount of RAM, the disk size and type etc
Step 2) RDP Connection: To initialize local DB server connect to the deployed instance, Please follow Instructions to Connect to Windows instance on Google Cloud
Step 3) SQL Connection: To Connect Microsoft SQL Server Management Studio in windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio
Step 4) Database Credentials: You can Login by below SQL Database credentials
SQL UserName : sa The below screen appears after successful deployment of the image.
i) Please connect to Remote Desktop as given in step 2 ii) You can use SQL server instance as localhost. The SQL Server instance name to be used is “localhost” Connect to SQL Management Studio with username as sa and password provided in Custom Metadata. If you have closed the deployment page you can also get the sa password from VM Details “Custom metadata” Section.
Step 5 ) Other Information:
1.Default installation path: “C:\Program Files\Microsoft SQL Server ”
2.Default ports:
- Windows Machines: RDP Port – 3389
- SQL server port:1433: By default, this is blocked on the Public interface for security reasons.
Videos
SQL Server 2017
1-click AWS Deployment 1-click Azure Deployment 1-click Google Deployment
Overview
Microsoft® SQL Server 2017 is now on the scene with more new features that offer faster processing, more flexibility of use, and greater cost savings as a result. SQL Server 2017 promises all that and much more of what corporate customers need at all levels. Database performance has reached a new peak with adaptive query processing, new flexibility with cross-platform capabilities, new integrations for statistical and data science analysis, and SQL Server versions on Linux®, Ubuntu® operating systems, or Docker®. The new version adds solid technology with cost savings.
Similar to other RDBMS software, SQL Server is built on top of SQL, a standard programming language for interacting with the relational databases. SQL server is tied to Transact-SQL, or T-SQL, the Microsoft’s implementation of SQL that adds a set of proprietary programming constructs.SQL Server works exclusively on Windows environment for more than 20 years. In 2016, Microsoft made it available on Linux. SQL Server 2017 became generally available in October 2016 that ran on both Windows and Linux.
SQL Server Architecture
The following diagram illustrates the architecture of the SQL Server:

SQL Server consists of two main components:
- Database Engine
- SQLOS
Database Engine
The core component of the SQL Server is the Database Engine. The Database Engine consists of a relational engine that processes queries and a storage engine that manages database files, pages, pages, index, etc. The database objects such as stored procedures, views, and triggers are also created and executed by the Database Engine.
Relational Engine
The Relational Engine contains the components that determine the best way to execute a query. The relational engine is also known as the query processor.The relational engine requests data from the storage engine based on the input query and processed the results.Some tasks of the relational engine include querying processing, memory management, thread and task management, buffer management, and distributed query processing.
Storage Engine
The storage engine is in charge of storage and retrieval of data from the storage systems such as disks and SAN.
SQL Server Services and Tools
Microsoft provides both data management and business intelligence (BI) tools and services together with SQL Server.For data management, SQL Server includes SQL Server Integration Services (SSIS), SQL Server Data Quality Services, and SQL Server Master Data Services. To develop databases, SQL Server provides SQL Server Data tools; and to manage, deploy, and monitor databases SQL Server has SQL Server Management Studio (SSMS).For data analysis, SQL Server offers SQL Server Analysis Services (SSAS). SQL Server Reporting Services (SSRS) provides reports and visualization of data. The Machine Learning Services technology appeared first in SQL Server 2016 which was renamed from the R Services.
SQL Server Editions
SQL Server has four primary editions that have different bundled services and tools. Two editions are available free of charge:
SQL Server Developer edition for use in database development and testing.
SQL Server Expression for small databases with the size up to 10 GB of disk storage capacity.
For larger and more critical applications, SQL Server offers the Enterprise edition that includes all SQL server’s features.
SQL Server Standard Edition has partial feature sets of the Enterprise Edition and limits on the Server regarding the numbers of processor core and memory that can be configured.
AWS
Installation Instructions for Windows
Step 1) RDP Connection: To connect to the deployed instance, Please follow Instructions to Connect to Windows instance on AWS Cloud
1) Connect to virtual machine using following RDP credentials:
- Hostname: PublicDNS / IP of machine
- Port : 3389
Username: To connect to the operating system, use RDP and the username is Administrator.
Password : Please Click here to know how to get password .
Step 2) SQL Connection: To Connect Microsoft SQL Server Management Studio in windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio
Step 3) Database Credentials: You can Login by windows authentication
Please change the password after the first login.
Step 4) Other Information:
1.Default ports:
- Windows Machines: RDP Port – 3389
- Http: 80
- Https: 443
- SQL Server Port: 1433 this is by default not allowed on the firewall for security.
Configure custom inbound and outbound rules using this link
Azure
Installation Instructions for Windows
Step 1) RDP Connection: To connect to the deployed instance, Please follow Instructions to Connect to Windows instance on Azure Cloud
1) Connect to virtual machine using following RDP credentials:
- Hostname: PublicDNS / IP of machine
- Port : 3389
Username: To connect to the operating system, use RDP and the username is Administrator.
Password : Please Click here to know how to get password .
Step 2) SQL Connection: To Connect Microsoft SQL Server Management Studio in windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio Local SQL Server sa password has been set as Passw@rd123
Step 3) Database Credentials: You can Login by below SQL Database credentials
SQL UserName : sa || Password : Passw@rd123
Note: You can reset ‘sa’ password by using windows authentication to connect to local SQL instance.Please use localhost in the server name when connecting from inside the RDC
Please change the password after the first login.
Step 4) Other Information:
1.Default ports:
- Windows Machines: RDP Port – 3389
- Http: 80
- Https: 443
- SQL Server Port: 1433 this is by default not allowed on the firewall for security.
2. VSCode and debug utilities have been installed
Installation Instructions for Windows
Step 1) VM Creation:
- Click the Launch on Compute Engine button to choose the hardware and network settings
- You can see at this page, an overview of Cognosys Image as well as estimated cost of running the instance.
- In the settings page, you can choose the number of CPUs and amount of RAM, the disk size and type etc
Step 2) RDP Connection: To initialize local DB server connect to the deployed instance, Please follow Instructions to Connect to Windows instance on Google Cloud
Step 3) SQL Connection: To Connect Microsoft SQL Server Management Studio in windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio
Step 4) Database Credentials: You can Login by below SQL Database credentials
SQL UserName : sa The below screen appears after successful deployment of the image.
i) Please connect to Remote Desktop as given in step 2 ii) You can use SQL server instance as localhost. The SQL Server instance name to be used is “localhost” Connect to SQL Management Studio with username as sa and password provided in Custom Metadata. If you have closed the deployment page you can also get the sa password from VM Details “Custom metadata” Section.
Step 5 ) Other Information:
1.Default installation path: “C:\Program Files\Microsoft SQL Server ”
2.Default ports:
- Windows Machines: RDP Port – 3389
- SQL server port:1433: By default, this is blocked on the Public interface for security reasons.
Videos
SQL Server 2017
