
1-click AWS Deployment 1-click Azure Deployment 1-click Google Deployment
Overview
SQL Server 2017 delivers breakthrough mission-critical capabilities with in-memory performance and operational analytics built-in. Comprehensive security features like new Always Encrypted technology helps protect your data at rest and in motion, and a world class high availability and disaster recovery solution adds new enhancements to AlwaysOn technology.Microsoft SQL Server 2017 is one of the leading database platforms, trusted by organizations worldwide. Since SQL Server 2008 R2, the SQL Server team has delivered over 100 significant new features.SQL Server 2017 offers substantial improvements and gives organizations choices of development languages, data types, on-premises or cloud, and operating systems (by bringing the power of SQL Server to Linux). It also includes support for Linux-based Docker containers and many other new, enhanced or performance improvements to the Database Engine, Integration Services (SSIS), Master Data Services (MDS), Analysis Services (SSAS), Reporting Services (SSRS), and Machine Learning Services.
SQL Server Architecture:
We have classified the architecture of SQL Server into the following parts for easy understanding −
- General architecture
- Memory architecture
- Data file architecture
- Log file architecture
General Architecture
Client − Where the request initiated.
Query − SQL query which is high level language.
Logical Units − Keywords, expressions and operators, etc.
N/W Packets − Network related code.
Protocols − In SQL Server we have 4 protocols.
- Shared memory (for local connections and troubleshooting purpose).
- Named pipes (for connections which are in LAN connectivity).
- TCP/IP (for connections which are in WAN connectivity).
- VIA-Virtual Interface Adapter (requires special hardware to set up by vendor and also deprecated from SQL 2012 version).
Server − Where SQL Services got installed and databases reside.
Relational Engine − This is where real execution will be done. It contains Query parser, Query optimizer and Query executor.
Query Parser (Command Parser) and Compiler (Translator) − This will check syntax of the query and it will convert the query to machine language.
Query Optimizer − It will prepare the execution plan as output by taking query, statistics and Algebrizer tree as input.
Execution Plan − It is like a roadmap, which contains the order of all the steps to be performed as part of the query execution.
Query Executor − This is where the query will be executed step by step with the help of execution plan and also the storage engine will be contacted.
Storage Engine − It is responsible for storage and retrieval of data on the storage system (disk, SAN, etc.,), data manipulation, locking and managing transactions.
SQL OS − This lies between the host machine (Windows OS) and SQL Server. All the activities performed on database engine are taken care of by SQL OS. SQL OS provides various operating system services, such as memory management deals with buffer pool, log buffer and deadlock detection using the blocking and locking structure.
Checkpoint Process − Checkpoint is an internal process that writes all dirty pages (modified pages) from Buffer Cache to Physical disk. Apart from this, it also writes the log records from log buffer to physical file. Writing of Dirty pages from buffer cache to data file is also known as Hardening of dirty pages.
It is a dedicated process and runs automatically by SQL Server at specific intervals. SQL Server runs checkpoint process for each database individually. Checkpoint helps to reduce the recovery time for SQL Server in the event of unexpected shutdown or system crash\Failure.
Checkpoints in SQL Server
In SQL Server 2012 there are four types of checkpoints −
- Automatic − This is the most common checkpoint which runs as a process in the background to make sure SQL Server Database can be recovered in the time limit defined by the Recovery Interval − Server Configuration Option.
- Indirect − This is new in SQL Server 2012. This also runs in the background but to meet a user-specified target recovery time for the specific database where the option has been configured. Once the Target_Recovery_Time for a given database has been selected, this will override the Recovery Interval specified for the server and avoid automatic checkpoint on such DB.
- Manual − This one runs just like any other T-SQL statement, once you issue checkpoint command it will run to its completion. Manual checkpoint runs for your current database only. You can also specify the Checkpoint_Duration which is optional – this duration specifies the time in which you want your checkpoint to complete.
- Internal − As a user you can’t control internal checkpoint. Issued on specific operations such as
- Shutdown initiates a checkpoint operation on all databases except when shutdown is not clean (shutdown with nowait).
- If the recovery model gets changed from Full\Bulk-logged to Simple.
- While taking backup of the database.
- If your DB is in simple recovery model, checkpoint process executes automatically either when the log becomes 70% full, or based on Server option-Recovery Interval.
- Alter database command to add or remove a data\log file also initiates a checkpoint.
- Checkpoint also takes place when the recovery model of the DB is bulk-logged and a minimally logged operation is performed.
- DB Snapshot creation.
- Lazy Writer Process − Lazy writer will push dirty pages to disk for an entirely different reason, because it needs to free up memory in the buffer pool. This happens when SQL server comes under memory pressure. As far as I am aware, this is controlled by an internal process and there is no setting for it.
SQL server constantly monitors memory usage to assess resource contention (or availability); its job is to make sure that there is a certain amount of free space available at all times. As part of this process, when it notices any such resource contention, it triggers Lazy Writer to free up some pages in memory by writing out dirty pages to disk. It employs Least Recently Used (LRU) algorithm to decide which pages are to be flushed to the disk.
If Lazy Writer is always active, it could indicate memory bottleneck.
Memory Architecture
Following are some of the salient features of memory architecture.
- One of the primary design goals of all database software is to minimize disk I/O because disk reads and writes are among the most resource-intensive operations.
- Memory in windows can be called with Virtual Address Space, shared by Kernel mode (OS mode) and User mode (Application like SQL Server).
- SQL Server “User address space” is broken into two regions: MemToLeave and Buffer Pool.
- Size of MemToLeave (MTL) and Buffer Pool (BPool) is determined by SQL Server during startup.
- Buffer management is a key component in achieving I/O highly efficiency. The buffer management component consists of two mechanisms: the buffer manager to access and update database pages, and the buffer pool to reduce database file I/O.
- The buffer pool is further divided into multiple sections. The most important ones being the buffer cache (also referred to as data cache) and procedure cache. Buffer cache holds the data pages in memory so that frequently accessed data can be retrieved from cache. The alternative would be reading data pages from the disk. Reading data pages from cache optimizes performance by minimizing the number of required I/O operations which are inherently slower than retrieving data from the memory.
- Procedure cache keeps the stored procedure and query execution plans to minimize the number of times that query plans have to be generated. You can find out information about the size and activity within the procedure cache using DBCC PROCCACHE statement.
Other portions of buffer pool include −
- System level data structures − Holds SQL Server instance level data about databases and locks.
- Log cache − Reserved for reading and writing transaction log pages.
- Connection context − Each connection to the instance has a small area of memory to record the current state of the connection. This information includes stored procedure and user-defined function parameters, cursor positions and more.
- Stack space − Windows allocates stack space for each thread started by SQL Server.
Data File Architecture
Data File architecture has the following components −
File Groups
Database files can be grouped together in file groups for allocation and administration purposes. No file can be a member of more than one file group. Log files are never part of a file group. Log space is managed separately from data space.
There are two types of file groups in SQL Server, Primary and User-defined. Primary file group contains the primary data file and any other files not specifically assigned to another file group. All pages for the system tables are allocated in the primary file group. User-defined file groups are any file groups specified using the file group keyword in create database or alter database statement.
One file group in each database operates as the default file group. When SQL Server allocates a page to a table or index for which no file group was specified when they were created, the pages are allocated from default file group. To switch the default file group from one file group to another file group, it should have db_owner fixed db role.
By default, primary file group is the default file group. User should have db_owner fixed database role in order to take backup of files and file groups individually.
Files
Databases have three types of files – Primary data file, Secondary data file, and Log file. Primary data file is the starting point of the database and points to the other files in the database.
Every database has one primary data file. We can give any extension for the primary data file but the recommended extension is .mdf. Secondary data file is a file other than the primary data file in that database. Some databases may have multiple secondary data files. Some databases may not have a single secondary data file. Recommended extension for secondary data file is .ndf.
Log files hold all of the log information used to recover the database. Database must have at least one log file. We can have multiple log files for one database. The recommended extension for log file is .ldf.
The location of all the files in a database are recorded in both master database and the primary file for the database. Most of the time, the database engine uses the file location from the master database.
Files have two names − Logical and Physical. Logical name is used to refer to the file in all T-SQL statements. Physical name is the OS_file_name, it must follow the rules of OS. Data and Log files can be placed on either FAT or NTFS file systems, but cannot be placed on compressed file systems. There can be up to 32,767 files in one database.
Extents
Extents are basic unit in which space is allocated to tables and indexes. An extent is 8 contiguous pages or 64KB. SQL Server has two types of extents – Uniform and Mixed. Uniform extents are made up of only single object. Mixed extents are shared by up to eight objects.
Pages
It is the fundamental unit of data storage in MS SQL Server. The size of the page is 8KB. The start of each page is 96 byte header used to store system information such as type of page, amount of free space on the page and object id of the object owning the page. There are 9 types of data pages in SQL Server.
- Data − Data rows with all data except text, ntext and image data.
- Index − Index entries.
- Tex\Image − Text, image and ntext data.
- GAM − Information about allocated extents.
- SGAM − Information about allocated extents at system level.
- Page Free Space (PFS) − Information about free space available on pages.
- Index Allocation Map (IAM) − Information about extents used by a table or index.
- Bulk Changed Map (BCM) − Information about extents modified by bulk operations since the last backup log statement.
- Differential Changed Map (DCM) − Information about extents that have changed since the last backup database statement.
Log File Architecture
The SQL Server transaction log operates logically as if the transaction log is a string of log records. Each log record is identified by Log Sequence Number (LSN). Each log record contains the ID of the transaction that it belongs to.
Log records for data modifications record either the logical operation performed or they record the before and after images of the modified data. The before image is a copy of the data before the operation is performed; the after image is a copy of the data after the operation has been performed.
The steps to recover an operation depend on the type of log record −
- Logical operation logged.
- To roll the logical operation forward, the operation is performed again.
- To roll the logical operation back, the reverse logical operation is performed.
- Before and after image logged.
- To roll the operation forward, the after image is applied.
- To roll the operation back, the before image is applied.
Different types of operations are recorded in the transaction log. These operations include −
- The start and end of each transaction.
- Every data modification (insert, update, or delete). This includes changes by system stored procedures or data definition language (DDL) statements to any table, including system tables.
- Every extent and page allocation or de allocation.
- Creating or dropping a table or index.
Rollback operations are also logged. Each transaction reserves space on the transaction log to make sure that enough log space exists to support a rollback that is caused by either an explicit rollback statement or if an error is encountered. This reserved space is freed when the transaction is completed.
The section of the log file from the first log record that must be present for a successful database-wide rollback to the last-written log record is called the active part of the log, or the active log. This is the section of the log required to a full recovery of the database. No part of the active log can ever be truncated. LSN of this first log record is known as the minimum recovery LSN (Min LSN).
The SQL Server Database Engine divides each physical log file internally into a number of virtual log files. Virtual log files have no fixed size, and there is no fixed number of virtual log files for a physical log file.
The Database Engine chooses the size of the virtual log files dynamically while it is creating or extending log files. The Database Engine tries to maintain a small number of virtual files. The size or number of virtual log files cannot be configured or set by administrators. The only time virtual log files affect system performance is if the physical log files are defined by small size and growth_increment values.
The size value is the initial size for the log file and the growth_increment value is the amount of space added to the file every time new space is required. If the log files grow to a large size because of many small increments, they will have many virtual log files. This can slow down database startup and also log backup and restore operations.
We recommend that you assign log files a size value close to the final size required, and also have a relatively large growth_increment value. SQL Server uses a write-ahead log (WAL), which guarantees that no data modifications are written to disk before the associated log record is written to disk. This maintains the ACID properties for a transaction.
SQL Server consistently leads in the TPC-E OLTP workload, the TPC-H data warehousing workload, and real-world application performance benchmarks. Get record-breaking performance now on Windows and Linux.
Cognosys Provides Hardened images of SQL Server 2017 on the cloud ( AWS marketplace, Azure and Google Cloud Platform) with multiple utilities to help in easy deployment.
Highest performing data warehouses
Get support for small data marts to large enterprise data warehouses while reducing storage needs with enhanced data compression. Scale to petabytes of data for enterprise-grade relational data warehousing—and integrate with non-relational sources like Hadoop.
SQL Server 2017 Ent with Vulnerability Assessment
Features
SQL Server is no longer just a windows-based relational database management system (RDBMS). You can run it on different flavors of the Linux operating systems. You can also develop applications with SQL Server on Linux, Windows, Ubuntu operating systems, or Docker and deploy them on these platforms.
Resumable online index rebuild
This feature resumes an online index rebuild operation from where it stopped after events such as database failovers, running out of disk space, or pauses.The following images show an example of this operation:
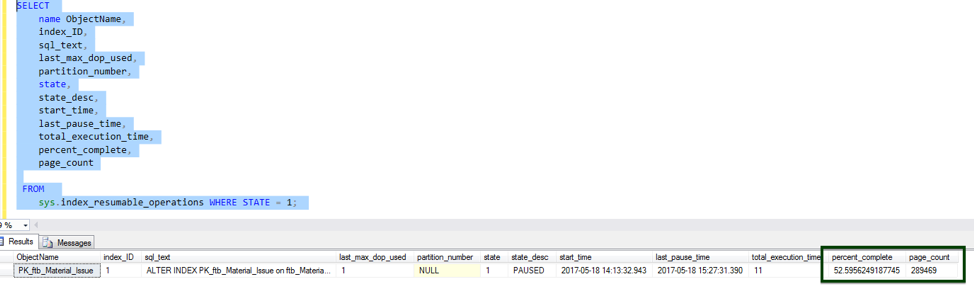
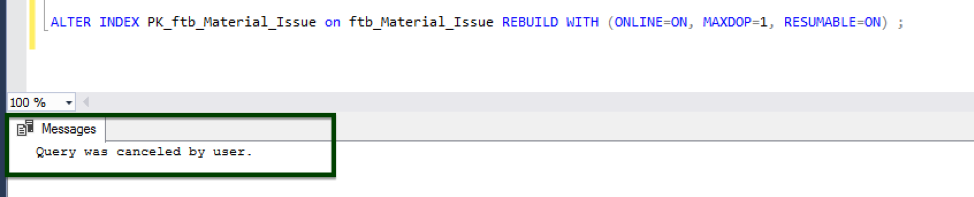
GUIDELINES FOR INDEXING
When you perform online index operations, the following guidelines apply:
- Clustered indexes must be created, rebuilt, or dropped offline when the underlying table contains image, ntext, and text large object (LOB) data types.
- Non-unique and non-clustered indexes can be created online when the table contains LOB data types but none of these columns are used in the index definition as either key or as non-key (included) columns.
- Indexes on local temporary tables cannot be created, rebuilt, or dropped online. This restriction does not apply to indexes on global temporary tables.
- You can perform concurrent online index data definition language (DDL) operations on the same table or view only when you are creating multiple new non-clustered indices, or reorganizing non-clustered indices. All other online index operations performed at the same time fail. For example, you cannot create a new index online while rebuilding an existing index online on the same table.
SQL Server machine learning services
SQL Server 2016 integrated the R programming language, which can be run within the database server and can be embedded into a Transact-SQL (T-SQL) script, too. In SQL Server 2017, you can execute the Python script within the database server itself. Both R and Python are popular programming languages that provide extensive support for data analytics along with natural language processing capability.
SQL Server 2017 adapts optimization strategies to your application workload’s runtime conditions. It includes adaptive query processing features that you can use to improve query performance in SQL Server and SQL Database.
There are three new query improvements as shown in the following diagram:

- Batch mode memory grant feedback: This feedback technique recalculates required memory for the execution plan and grants it from cache.
- Batch mode adaptive joins: To execute the plan faster, this technique can use a hash join or a nested loop join. After scanning the first input of the execution plan, it decides which join to use to produce output at the fastest speed.
- Interleaved execution: Interleaved execution pauses optimization of an execution plan when it encounters multi-statement table-valued functions. Then, it calculates perfect cardinality and resumes optimization.
This feature notifies you whenever a potential performance issue is detected and enables you to apply corrective actions, or it enables the database engine to automatically fix performance issues caused by the SQL plan choice regressions. Thus, the database can dynamically adapt to your workload by finding what indexes and plans might improve performance of your workloads and what indexes affect your workloads. Based on these findings, the automatic tuning process applies actions that improve the workload performance. In addition, the database continuously monitors performance after any change made by automatic tuning to ensure that it improves the workload performance. Any action that doesn’t improve performance is automatically reverted.
SQL PLAN CHOICE REGRESSION
The SQL Server database engine may use different SQL plans to execute the T-SQL queries. Query plans depend on the statistics, indexes, and other factors. In some cases, the new plan might not be better than the previous one, and the new plan might cause a performance regression. Whenever you notice a poor plan choice regression, you should find a previously used good plan and force it to be used instead of the current one by using the sp_query_store_force_plan procedure. The database engine in SQL Server 2017 (v. 14.x) provides information about regression plans and recommended corrective actions. Additionally, the database engine enables you to fully automate this process and let the database engine fix any problems related to the plan changes that are found.
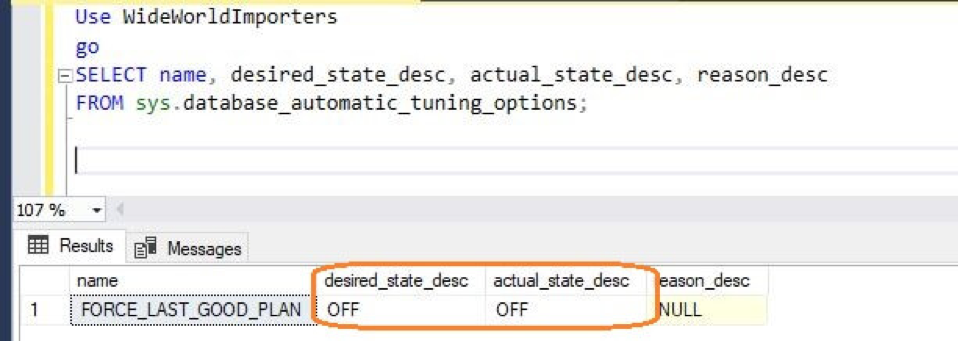
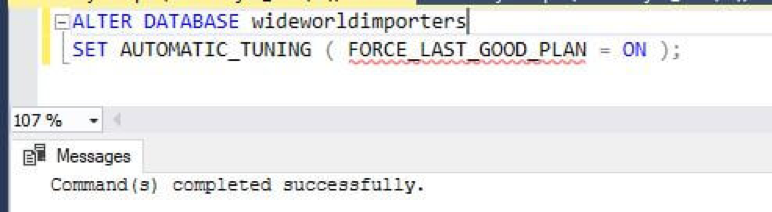
AUTOMATIC PLAN CORRECTION
The automatic plan correction is shown in the following diagram:

The following automatic tuning features are available:
- Automatic plan correction (available in SQL Server 2017 v14.x and Azure SQL Database): It identifies problematic query execution plans and fixes the SQL plan performance problems. Automatic tuning is enabled using the following command:
- Automatic index management (available only in Azure SQL Database): It identifies indexes that should be added in your database and indexes that should be removed.
SQL Server 2017 setup now enables you to specify the initial TempDB file size up to 256 GB (262,144 MB) per file, with a warning if the file size is set greater than 1GB without instant file initialization (IFI) enabled. It is important to understand that, depending on the initial size of TempDB data file specified, not enabling IFI can cause setup time to increase exponentially.
A new column modified_extent_page_count is introduced in sys.dm_db_file_space_usage to track differential changes in each database file in the database. The new column modified_extent_page_count allows DBAs, the SQL community, and backup independent software vendors (ISVs) to build smart backup solutions, which perform differential backups if the percentage of changed pages in the database is below a threshold (approximately 70-80%). Otherwise, they perform a full database backup. With a large number of changes in the database, the cost and time to complete differential backups is similar to taking a full database backup, so there is no real benefit of taking differential backup in this case. However, it can certainly increase the restore time of database. By adding this intelligence to the backup solutions, you can now save on restore and recovery time by using differential backups.
A new Dynamic Management Function (DMF), sys.dm_db_log_stats (database_id), was released. This function exposes a new column, log_since_last_log_backup_mb, which empowers DBAs, the SQL community, and backup ISVs to build intelligent T-log backup solutions to take backups based on the transactional activity on the database. This T-log backup solution intelligence ensures that, if the T-log backup frequency is too low, the transaction log size doesn’t grow due to a high burst of transactional activity in a short time. It also helps to avoid a situation where the scheduled transaction log backup creates too many T-log backup files even when there is no transactional activity on the server. If that happened, it would add unnecessarily to the storage, file management, and restore overheads.
Improved SELECT INTO statement
In SQL Server 2017, you can provide the filegroup name on which to create a new table by using the ON keyword with the SELECT INTO statement. The table is created on the default filegroup of the user by default. This functionality was not available in previous versions.
Distributed transaction support
SQL Server 2017 supports distributed transactions for databases in availability groups. This support includes databases on the same instance of SQL Server and databases on different instances of SQL Server. Distributed transactions are not supported for databases configured for database mirroring.
New availability groups functionality
This functionality includes clusterless support, the Minimum Replica Commit Availability Groups setting, and Windows-Linux cross-OS migrations and testing.
This functionality includes the following features:
- Availability groups can now be set up without an underlying cluster (Windows Server Failover Cluster or WSFC) and across mixed environments (instances on Windows and Linux or Docker).
- The new Minimum Replica Commit setting enables you to dictate a certain number of secondary replicas. You must commit a transaction before committing on the primary.
The dynamic management views (DMVs) include the following elements:
- sys.dm_db_log_stats exposes summary level attributes and information on transaction log files and is helpful for monitoring transaction log health.
- sys.dm_tran_version_store_space_usage enables you to see the impact on version store usage, grouped by each database. As a result, you can use this to profile your workload in a test environment (before and after the change) and to monitor the impact over time–even if other databases are also using version store.
- sys.dm_db_log_info exposes virtual log file (VLF) information to monitor, alert, and avert potential transaction log issues.
- sys.dm_d_stats_histogram is a new dynamic management view for examining statistics, as shown in the following image:
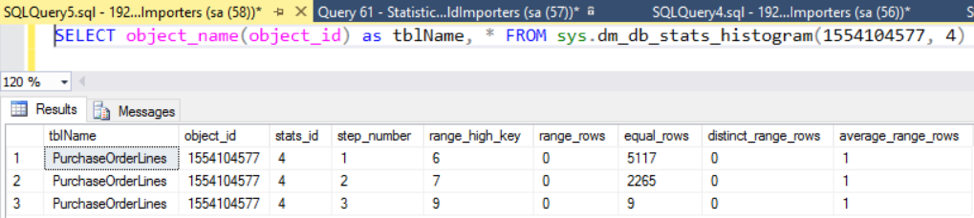
- sys.dm_os_host_info exposes things like platform, distribution, service pack level, and language.
- sys.dm_os_sys_info was expanded, revealing CPU information (such as socket count, core count, and cores per socket).
The in-memory changes in SQL Server 2017 include the following enhancements:
- Computed column, and indexes on those columns, are now supported.
- CASE expressions, CROSS APPLY, and TOP (N) WITH TIES are now supported in natively-compiled modules.
- JSON commands are now fully supported in both check constraints and in natively-compiled modules.
- The system procedure sp_spaceused now properly reports space for memory-optimized tables.
- The system procedure sp_rename now works on in-memory tables and natively-compiled modules.
- The limitation of eight indexes on memory-optimized tables has been eliminated.
- Memory-optimized filegroup files can now be stored on Azure storage.
You can now grant, deny, or revoke permissions on database-scoped credentials such as CONTROL, ALTER, REFERENCES, TAKE OWNERSHIP, and VIEW DEFINITION permissions. Also, ADMINISTER DATABASE BULK OPERATIONS is now visible in sys.fn_builtin_permissions.
High availability and disaster recovery
Gain mission-critical uptime, fast failover, easy setup, and load balancing of readable secondaries with enhanced Always On functionality in SQL Server 2017. This is a unified solution for high availability and disaster recovery on Linux and Windows. You can also put an asynchronous replica in an Azure virtual machine for hybrid high availability.
SQL Server 2017 introduces the following changes to the way queries and statistics are collected and displayed:
- A new DMV sys.dm_exec_query_statistics_xml allows you to correlate sessions to plans, as long as query profiling is enabled. The following image illustrates this:

- Showplan XML now includes information about the statistics used for a plan and, for actual plans, runtime metrics and the top 10 wait statistics experienced by that plan. These wait statistics are also now being tracked in the query store.
- A new dynamic management function sys.dm_db_stats_histogram enables you to access histogram information programmatically, without databases console commands (DBCC).
–Major Features of SQL Server :
-
Security and compliance
Protect data at rest and in motion with a database that has the least vulnerabilities of any major platform for six years running in the NIST vulnerabilities database (National Institute of Standards and Technology, National Vulnerability Database, Jan 17, 2017). Security innovations in SQL Server 2017 help secure data for mission-critical workloads with a layers of protection security approach, adding Always Encrypted technology along with row-level security, dynamic data masking, transparent data encryption (TDE), and robust auditing.
-
High availability and disaster recovery
Gain mission-critical uptime, fast failover, easy setup, and load balancing of readable secondaries with enhanced Always On in SQL Server 2017—a unified solution for high availability and disaster recovery on Linux and Windows. Plus, put an asynchronous replica in an Azure Virtual Machine for hybrid high availability.
-
Corporate business intelligence
Scale your business intelligence (BI) models, enrich your data, and ensure quality and accuracy with a complete BI solution. SQL Server Analysis Services help you build comprehensive, enterprise-scale analytic solutions—benefiting from the lightning-fast performance of in-memory built into the tabular model. Reduce time to insights using direct querying against tabular and multidimensional models.
-
End-to-end mobile BI on any device
Gain insights and transform your business with modern, paginated reports and rich visualizations. Use SQL Server Reporting Services to publish reports to any mobile device—including Windows, Android, and iOS devices—and access reports online or offline.
-
Simplify data big and small
Combine relational data and big data with PolyBase technology that queries Hadoop using simple T-SQL commands. JSON support lets you parse and store JSON documents and output relational data into JSON files. Now in SQL Server 2017, manage and query graph data inside your relational database.
-
In-database advanced analytics
Build intelligent applications with SQL Server Machine Learning Services using R and Python. Move beyond reactive and into predictive and prescriptive analytics by performing advanced analytics directly within the database. By using multi-threading and massively parallel processing, you’ll gain insights faster than using open source R and Python alone.
-
Real-time hybrid transactional/analytical processing
Combine in-memory columnstore and rowstore capabilities in SQL Server 2017 for real-time operational analytics—fast analytical processing right on your transactional data. Open up new scenarios like real-time fraud detection without impacting your transactional performance.
-
Now on Windows, Linux and Docker
Develop once and deploy anywhere with our consistent experience from on-premises to cloud. Now with support for Windows and Linux as well as Docker containers.
-
Consistent data platform from on-premises to cloud
Get a consistent experience from on-premises to the cloud—letting you build and deploy hybrid solutions for managing your data investments. Benefit from the flexibility to run SQL Server workloads in Azure Virtual Machines, or use Azure SQL Database to scale and further simplify database management.
-
Easy-to-use tools and connectors
Use the skills you already have, along with familiar tools like Azure Active Directory and SQL Server Management Studio, to manage your database infrastructure across on-premises SQL Server and Microsoft Azure. Apply industry-standard APIs across various platforms and download updated developer tools from Visual Studio to build next-generation web, enterprise, business intelligence, and mobile applications.
AWS
Installation Instructions For Windows
Installation Instructions for Windows
Step 1) RDP Connection: To connect to the deployed instance, Please follow Instructions to Connect to Windows instance on AWS Cloud
1) Connect to virtual machine using following RDP credentials:
- Hostname: PublicDNS / IP of machine
- Port : 3389
Username: To connect to the operating system, use RDP and the username is Administrator.
Password : Please Click here to know how to get password .
Step 2) SQL Connection: To Connect Microsoft SQL Server Management Studio in windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio
Step 3) Database Credentials: You can Login by below SQL Database credentials
SQL UserName : sa || Password : Passw@rd123
Note: You can reset ‘sa’ password by using windows authentication to connect to local SQL instance.Please use localhost in the server name when connecting from inside the RDC
Please change the password after the first login.
Step 4) Other Information:
1.Default ports:
- Windows Machines: RDP Port – 3389
- Http: 80
- Https: 443
- SQL Server Port: 1433 this is by default not allowed on the firewall for security.
Configure custom inbound and outbound rules using this link
Installation Step by Step Screenshots
Azure
Installation Instructions For Windows
Installation Instructions for Windows
Step 1) RDP Connection: To connect to the deployed instance, Please follow Instructions to Connect to Windows instance on Azure Cloud
1) Connect to virtual machine using following RDP credentials:
- Hostname: PublicDNS / IP of machine
- Port : 3389
Username: To connect to the operating system, use RDP and the username is Administrator.
Password : Please Click here to know how to get password .
Step 2) SQL Connection: To Connect Microsoft SQL Server Management Studio in windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio
Local SQL Server sa password has been set as Passw@rd123
Step 3) Database Credentials: You can Login by below SQL Database credentials
SQL UserName : sa || Password : Passw@rd123
Note: You can reset ‘sa’ password by using windows authentication to connect to local SQL instance.Please use localhost in the server name when connecting from inside the RDC
Please change the password after the first login.
Step 4) Other Information:
1.Default ports:
- Windows Machines: RDP Port – 3389
- Http: 80
- Https: 443
- SQL Server Port: 1433 this is by default not allowed on the firewall for security.
2. VSCode and debug utilities have been installed
