
1-click AWS Deployment 1-click Azure Deployment
Overview
Introduction to MySQL Relational Database Management System (RDBMS)
SQL is a programming language for interacting with relational databases. On the other hand, MySQL is a software system – a Relational Database Management System.MySQL is one of the most used, industrial-strength, opensource and free Relational Database Management System (RDBMS). MySQL was developed by Michael “Monty” Widenius and David Axmark in 1995. It was owned by a Swedish company called MySQL AB, which was bought over by Sun Microsystems in 2008. Sun Microsystems was acquired by Oracle in 2010.
MySQL is successful, not only because it is free and open-source (there are many free and open-source databases, such as PostgreSQL, Apache Derby (Java DB), mSQL (mini SQL), SQLite and Apache OpenOffice’s Base), but also for its speed, ease of use, reliability, performance, connectivity (full networking support), portability (run on most OSes, such as Unix, Windows, macOS), security (SSL support), small size, and rich features. MySQL supports all features expected in a high-performance relational database, such as transactions, foreign key, replication, subqueries, stored procedures, views and triggers.
MySQL is often deployed in a LAMP (Linux-Apache-MySQL-PHP), WAMP (Windows-Apache-MySQL-PHP), or MAMP (macOS-Apache-MySQL-PHP) environment. All components in LAMP is free and open-source, inclusive of the Operating System.
The mother site for MySQL is https://www.mysql.com. The ultimate reference for MySQL is the “MySQL Reference Manual”, available at https://dev.mysql.com/doc. The reference manual is huge – the PDF has over 3700 pages!!!
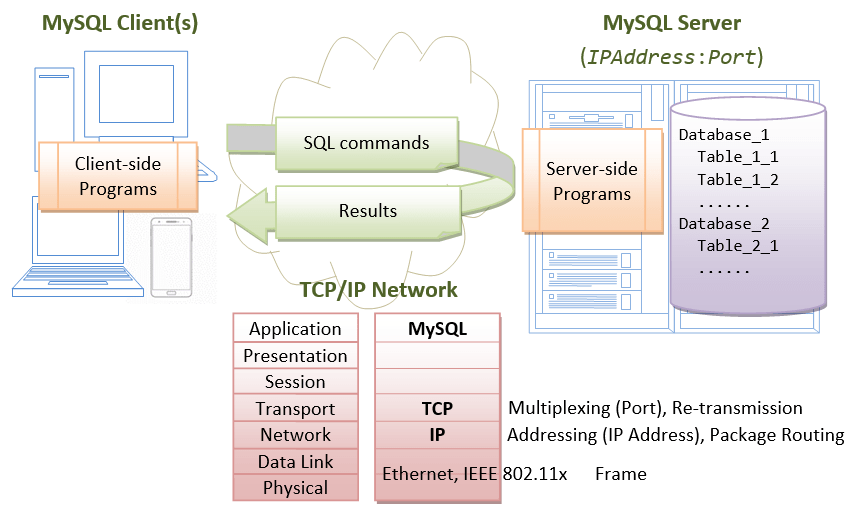
MySQL operates as a client-server system over TCP/IP network. The server runs on a machine with an IP address on a chosen TCP port number. The default TCP port number for MySQL is 3306. Users can access the server via a client program, connecting to the server at the given IP address and TCP port number.
MySQL 8.0: Data Dictionary Architecture and Design
The MySQL Data Dictionary Schema

Upgrade from 8.0 and forward
The data dictionary will have a version table. This will enable automatic upgrade from 8.0 and forward on data dictionary tables.
I_S as views over Data Dictionary Tables
INFORMATION SCHEMA is now implemented as views over dictionary tables, requires no extra disc accesses, no creation of temporary tables, and is subject to similar handling of character sets and collations as user tables.

An API for the Data Dictionary
We will implement a uniform API for the data dictionary. This API will then be used by server internal code, plugin service API code and storage engines, through the SE API. This will be done in a manner that has low intrusiveness for the server code that access the data dictionary, so code can be refactored piecewise.
The new Data Dictionary cache
There are many caches in MySQL, and these caches are not always hidden behind APIs. A new cache implementation aims to be a replacement for many caches, and this new cache is hidden behind the data dictionary API. For now, we have not replaced any old caches, but enhanced them to use the new cache. Going forward we will refactor the old caches, create proper APIs for them and adapt the code of the callers. This will simplify the code of the callers, and move all the cache logic behind the API.
The new SE API for atomic and crashsafe DDL
We do want to provide atomic and crashsafe DDL, and this requires changes to the MySQL server DDL code, and the InnoDB code where dictionary tables are stored. The MySQL server code will remove all implicit commits and implement clear atomic semantics for DDL statements. To enable this, the tables must be stored in a transactional storage engine, and we will use InnoDB.
With the new SE API, we are able to implement crashsafe DDL, as the storage of the data dictionary is InnoDB, which inherently has transational behaviour.
Serialized Dictionary Information and changes to the IMPORT statement
Many users have showed love for the ability to copy table data and FRM files into the DATA DIRECTORY and have the MySQL server automatically picking up these tables. This capability has also been utilized for disaster recovery, where .FRM “blackbelts” have been able to reconstruct the meta data in the .FRM file. In MySQL 8.0 we provide Serialized Dictionary information for dictionary objects. For InnoDB tablespaces, this information is appended to the tablespace, so the meta data and data are bundled together. For storage engines which are not supporting this functionality, a .SDI file will be written.

For InnoDB tablespaces, a tool will be provided to read the SDI information. The SDI information is JSON format. So the same capability of modifying the SDI as users have with .FRM files for disaster recovery is provided.
Database schema change is becoming more frequent than before, Four out of five application updates(Releases) requires a corresponding database change, For a DBA schema change is a more often a repetitive task, it might be a request from the application team for adding or modifying columns in a table and many more cases.
MySQL supports online DDL from 5.6 and the latest MySQL 8.0 supports instant columns addition.
This blog post will look at the online DDL algorithms inbuilt which can be used to perform schema changes in MySQL.
DDL Algorithms supported by InnoDB is,
- COPY
- INPLACE
- INSTANT ( from 8.0 versions)
INPLACE Algorithm:
INPLACE algorithm performs operations in-place to the original table and avoids the table copy and rebuild, whenever possible.
If the INPLACE algorithm is specified with the ALGORITHM clause if the ALTER TABLE operation does not support the INPLACE algorithm, then an alter will be exited with an error by suggesting possible algorithm which can be used.
mysql> alter table sbtest1 add column h int(11) default null,algorithm=inplace; Query OK, 0 rows affected (14.12 sec) Records: 0 Duplicates: 0 Warnings: 0
INPLACE algorithm is dependent on two important variables when it performs the table operation.
- It uses tmp dir to write sort files, in the defined tmp dir(uses /tmp by default), if defined tmp dir is not enough, we can explicitly define by the
innodb_tmpdirsystem variable. - It also uses a temporary log file called innodb_online_alter_log_max_size to track data changes by DML queries executed like
INSERT,UPDATE,DELETEin the table during the DDL operation, The maximum size for this log file can be configured by the dynamic variableinnodb_online_alter_log_max_size(default is 128MB) system variable.
the incoming writes during the process of altering are stored with a size defined in innodb_online_alter_log_max_size are applied at the end of the DDL operation by locking the table for some seconds based on the write rate.
If the incoming writes floods the innodb_online_alter_log_max_size defined size, then DDL operation fails and the uncommitted transactions are rolled back.
Example:
mysql> alter table sbtest.sbtest5 add column l varchar(100),algorithm=inplace; ERROR 1799 (HY000): Creating index 'PRIMARY' required more than 'innodb_online_alter_log_max_size' bytes of modification log. Please try again.
Below is an internal flow of INPLACE algorithm, when some operations perform a table rebuilt.

The below table provides operations that use an online DDL with INPLACE algorithm to perform table rebuilt.

Note: The InnoDB needs extra disk space to perform the above-listed operations, either equal to the size of the original table in the datadir or more in some cases.
Drawbacks of ‘INPLACE’ algorithm
- Long-running online DDL operations can cause replication lag in slaves. Online DDL operation must finish running on the master before it is run on the slave. Also, DML that was processed concurrently on the master is only processed on the slave after the DDL operation on the slave is completed.
- larger
innodb_online_alter_log_max_sizesize extends the period of time at the end of the DDL operation when the table is locked to apply the data from the log. - At time can cause high IO usage for a larger table at high concurrency servers ( Aggressive in terms of resource consumption)
COPY Algorithm
Algorithm COPY alters the schema of the existing table by creating a new temporary table with the altered schema, once it migrates the data completely to the new temporary table it swaps and drops the old table.
Example:
mysql> alter table sbtest1 modify column h varchar(20) not null,algorithm=inplace; ERROR 1846 (0A000): ALGORITHM=INPLACE is not supported. Reason: Cannot change column type INPLACE. Try ALGORITHM=COPY.
When the INPLACE algorithm is not supported, MySQL throws an error and prescribes using COPY algorithm.
mysql> alter table sbtest1 modify column h varchar(20) not null,algorithm=COPY; Query OK, 1024578 rows affected (17.95 sec) Records: 1024578 Duplicates: 0 Warnings: 0
ALTER TABLE with ALGORITHM=COPY is an expensive operation as it blocks concurrent DML’s (inserts,updates,deletes) operations, but it allows concurrent read queries(SELECT’S) when LOCK=SHARED.
if the lock mode LOCK=EXCLUSIVE is used, both reads/writes are blocked until the completion of the alter.
Below is an internal flow of the COPY algorithm when it creates a copy of a table.

Drawbacks of COPY Algorithm
- There is no mechanism to pause a DDL operation or to throttle I/O or CPU usage during the operation.
- Rollback of operation can be an expensive process.
- Blocks Concurrent DML’s are not allowed during the ALTER table
- Causes replication lag
INSTANT Algorithm
In further improvement in online DDL’s ( column addition ) MySQL 8.0 has come up INSTANT algorithm ( a patch from TENCENT ) . This feature makes instant and in-place table alterations for column addition and allows concurrent DML with Improved responsiveness and availability in busy production environments.
If ALGORITHM is not specified, the server will first try the DEFAULT=INSTANT algorithm for all column addition. If it can not be done, then the server will try INPLACE algorithm; and if that can not be supported, at last server will finally try COPY algorithm.
INSTANT algorithm performs only metadata changes in the data dictionary. It doesn’t acquire any metadata lock during schema changes and as it doesn’t touch the data file of the table.
Example:
mysql> alter table city add pincode int(11) default null, algorithm=INSTANT; Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0
The INSTANT algorithm supports only a few of the operations which are listed below.

I_S.innodb_tables and I_S.innodb_columns . Example :
Table structure before adding a column using INSTANT.
mysql> show create table sbtest.sbtest7\G *************************** 1. row *************************** Table: sbtest7 Create Table: CREATE TABLE `sbtest7` ( `id` int(11) NOT NULL AUTO_INCREMENT, `k` int(11) NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', `f` varchar(200) DEFAULT NULL, PRIMARY KEY (`id`), KEY `k_7` (`k`) ) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec)
When we query the innodb_tables table, the number of instant_columns will be zero.
mysql> SELECT table_id, name, instant_cols FROM information_schema.innodb_tables where name like '%sbtest7%'; +----------+----------------+--------------+ | table_id | name | instant_cols | +----------+----------------+--------------+ | 1258 | sbtest/sbtest7 | 0 | +----------+----------------+--------------+ 1 row in set (0.00 sec)
Let’s add a column using INSTANT algorithm,
mysql> alter table sbtest7 add g varchar(100) not null default 'Mysql 8 is great', algorithm=instant; Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0
after adding column instant_cols becomes 5.
mysql> SELECT table_id, name, instant_cols FROM information_schema.innodb_tables where name like '%sbtest7%'; +----------+----------------+--------------+ | table_id | name | instant_cols | +----------+----------------+--------------+ | 1258 | sbtest/sbtest7 | 5 | +----------+----------------+--------------+ 1 row in set (0.00 sec)
This means that instant_cols keeps a track of the number of columns present in table sbtest7 before an instant column addition.
And the default values of columns that are added by the INSTANT algorithm are stored in the I_S.innodb_columns table.
mysql> SELECT table_id, name, has_default, default_value FROM information_schema.innodb_columns WHERE table_id = 1258; +----------+------+-------------+----------------------------------+ | table_id | name | has_default | default_value | +----------+------+-------------+----------------------------------+ | 1258 | id | 0 | NULL | | 1258 | k | 0 | NULL | | 1258 | c | 0 | NULL | | 1258 | pad | 0 | NULL | | 1258 | f | 0 | NULL | | 1258 | g | 1 | 4d7973716c2038206973206772656174 | +----------+------+-------------+----------------------------------+ 6 rows in set (0.23 sec
Column g has_deafult value 1 and default_valuestored in hash format.
Drawbacks of INSTANT algorithm
- A column can only be added as the last column of the table. Adding a column to any other position among other columns is not supported.
- Columns cannot be added to tables that use
ROW_FORMAT=COMPRESSED. - Columns cannot be added to tables that include a FULLTEXT index.
- Columns cannot be added to temporary tables. Temporary tables only support
ALGORITHM=COPY. - Columns cannot be added to tables that reside in the data dictionary tablespace(shared tablespace).
Comparison of INPLACE, COPY AND INSTANT Algorithms.
We are the end of the blog the let us calculate the time difference between all 3 algorithm over a table with 1M records.
INPLACE – 7.09 sec
mysql> alter table sbtest7 add g varchar(100) not null default 0, algorithm=inplace; Query OK, 0 rows affected (7.09 sec) Records: 0 Duplicates: 0 Warnings: 0
COPY – 14.34 sec
mysql> alter table sbtest7 add g varchar(100) not null default 0, algorithm=copy; Query OK, 1000000 rows affected (14.34 sec) Records: 1000000 Duplicates: 0 Warnings: 0
INSTANT – 0.03 sec
mysql> alter table sbtest7 add g varchar(100) not null default 0, algorithm=instant; Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0

As we can see, using INSTANT the column was added in no time (just 0.03secs) when compared to the other two algorithms.
Key Takeaways:
INSTANTwill be the right algorithm to choose when our current MySQL Version is greater than 8 and also based on Alter type which we are trying to achieve.- Using the
COPYalgorithm for larger tables, with more no of async slaves, will be an expensive operation. - For alternatives, we can use other tools like pt-online-schema-change or gh-ost for schema changes, which provides more options for throttling the resource usage and more control.
MySQL workbench ER diagram forward engineering
MySQL workbench has utilities that support forward engineering. Forward engineering is a technical term is to describe the process of translating a logical model into a physical implement automatically.
We created an ER diagram on our ER modeling tutorial. We will now use that ER model to generate the SQL scripts that will create our database.
Creating the MyFlix database from the MyFlix ER model
1. Open the ER model of MyFlix database that you created in earlier tutorial.
2. Click on the database menu. Select forward engineer

3. The next window, allows you to connect to an instance of MySQL server. Click on the stored connection drop down list and select local host. Click Execute

4. Select the options shown below in the wizard that appears. Click next.
5. The next screen shows the summary of objects in our EER diagram. Our MyFlix DB has 5 tables. Keep the selections default and click Next.
6.. The window shown below appears. This window allows you to preview the SQL script to create our database. We can save the scripts to a *.sql” file or copy the scripts to the clipboard. Click on next button.
7. The window shown below appears after successfully creating the database on the selected MySQL server instance.
Point to note:
- Creating a database involves translating the logical database design model into the physical database.
- MySQL supports a number of data types for numeric, dates and strings values.
- CREATE DATABASE command is used to create a database
- CREATE TABLE command is used to create tables in a database
- MySQL workbench supports forward engineering which involves automatically generating SQL scripts from the logical database model that can be executed to create the physical database
–MySQL is the most popular Open Source Relational SQL database management system. MySQL is one of the best RDBMS being used for developing web-based software applications.MySQL is a fast, easy-to-use RDBMS being used for many small and big businesses.
MySQL is owned by MySQL (https://www.mysql.com/h) and they own all related trademarks and IP rights for this software.
Cognosys provides hardened images of MySQL Web Edition on all public cloud i.e. AWS marketplaceand Azure.
MySQL is the most trusted and widely used open source database platform in use today. 10 out of the top 10 most popular and highly-trafficked websites in the world rely on MySQL. MySQL 8.0 builds on this momentum by delivering across the board improvements designed to enable innovative DBAs and developers to create and deploy the next generation of web, embedded, mobile and Cloud/SaaS/PaaS/DBaaS applications on the latest generation of development frameworks and hardware platforms. MySQL 8.0 highlights include:
- MySQL Document Store
- Transactional Data Dictionary
- SQL Roles
- Default to utf8mb4
- Common Table Expressions
- Window Functions
Features
–Major Features of MYSQL 8.0
- Data dictionary : MySQL now incorporates a transactional data dictionary that stores information about database objects. In previous MySQL releases, dictionary data was stored in metadata files and nontransactional tables.
- Atomic Data Definition Statements (Atomic DDL) : An atomic DDL statement combines the data dictionary updates, storage engine operations, and binary log writes associated with a DDL operation into a single, atomic transaction.
- Security and account management : It added to improve security and enable greater DBA flexibility in account management.
- Resource management : MySQL now supports creation and management of resource groups, and permits assigning threads running within the server to particular groups so that threads execute according to the resources available to the group. Group attributes enable control over its resources, to enable or restrict resource consumption by threads in the group. DBAs can modify these attributes as appropriate for different workloads.
- Data type support : MySQL now supports use of expressions as default values in data type specifications. This includes the use of expressions as default values for the BLOB,TEXT,GEOMETRY and JSON data types, which previously could not be assigned default values at all.
- Common table expressions : MySQL now supports common table expressions, both nonrecursive and recursive. Common table expressions enable use of named temporary result sets, implemented by permitting a WITH clause preceding SELECT statements and certain other statements.
- Replication : MySQL Replication now supports binary logging of partial updates to JSON documents using a compact binary format, saving space in the log over logging complete JSON documents. Such compact logging is done automatically when statement-based logging is in use, and can be enabled by setting the new binlog_row_value_options system variable to PARTIAL_JSON.
- Logging : Error logging was rewritten to use the MySQL component architecture. Traditional error logging is implemented using built-in components, and logging using the system log is implemented as a loadable component. In addition, a loadable JSON log writer is available. To control which log components to enable, use the log_error_services system variable.
Azure
Note: How to find PublicDNS in Azure
Step1 ) RDP Connection: To connect to the deployed instance, Please follow Instructions to Connect to Windows instance on Azure Cloud
Connect to virtual machine using following RDP credentials:
- Hostname: PublicDNS / IP of machine
- Port : 3389
Username: Your chosen username when you created the machine ( For example: Azureuser)
Password : Your Chosen Password when you created the machine ( How to reset the password if you do not remember)
Step 2) Database Login Details:
Please use MySQL root password Passw@rd123 for the MySQL configuration.
Step 3) Choose Start, expand All Programs, and then select PHP
Step 4) Other Information:
1.Default installation path: will be in your root folder “C:inetpubwwwroot”
2.Default ports:
- Windows Machines: RDP Port – 3389
- Http: 80
- Https: 443
Configure custom inbound and outbound rules using this link
Videos
MYSQL 8.0 on Cloud

{kind=link}
{kind=link}
{kind=link}