1-click AWS Deployment 1-click Google Deployment
Overview
Microsoft SQL Server is an accessible, high-performance database management system. Designed to meet the requirements of distributed client-server computing, SQL Server enables organizations to improve decision-making and streamline business processes. Microsoft SQL Server is your solution to complex business problems. It offers reduced complexity for users, administrators and developers as well as quicker, easier-to-use business solutions at lower costs.Microsoft SQL Server Enterprise Edition is the complete database and analysis offering that rapidly delivers the next generation of scalable e-commerce, line-of-business and data warehousing solutions. It includes the complete set of SQL Server database and analysis features and is uniquely characterized by several features that make it the most scalable and available edition of SQL Server. It scales to the performance levels required to support the largest Web sites and enterprise online transaction processing (OLTP) and data warehousing systems. Its support for fail over clustering also makes it ideal for any mission critical line-of-business application.
Microsoft build SQL 2016 keeps a lot of things in mind like Cloud first, Security enhancement, JSON support, Temporal database support, Row level security, Windows server 2016 connectivity, Non-relational database connectivity (e.g. Hadoop), rich visual effects, etc. With SQL Server 2016, you can build intelligent, mission-critical applications using a scalable, hybrid database platform that has everything built in, from in-memory performance and advanced security to in-database analytics. The SQL Server 2016 release adds new security features, querying capabilities, Hadoop and cloud integration, R analytics and more, along with numerous improvements and enhancements.
Best among SQL Enterprise and SQL Standard :
The two SQL Server editions both have similar features for management tools, RDBMS Manageability, Development Tools, and Programmability. Despite many similarities between the two editions, it is clear that Enterprise delivers more functionality than the other editions of SQL Server, including the Standard edition. A company that has a need for all the additional features and scalability of Microsoft SQL Enterprise, should opt for this edition. Whereas, smaller organizations may be able to utilize the foundation offered by SQL Server Standard edition.
Microsoft SQL Enterprise
Microsoft SQL Server Enterprise includes everything in the Standard edition, but has additional features. The Enterprise SQL Server is optimal for companies focusing on scalability and performance.
Pros:
1.Adaptability to future technology enhancements
2.Reduced complexity
3.Professional, enterprise-level database management, such as supporting triggers for Microsoft products and close integration with the .NET framework.
4.Easy to configure
5.Dynamic Resource Allocation – disk and memory usage can scale to meet the changing demands on the infrastructure
6.Free version available for development or the educational industry with minor limitations compared to the full version.
7.iSQL – this essential tool enables users to perform interactive queries and build stored procedures, then view them in a graphical representation to display the steps the processor will use to execute.
Cons:
1.No Cascading DRI – Triggers can be a workaround for this missing component, but since every other competitor includes this feature, this is a significant shortcoming.
2.Limited Compatibility – The solution is designed to only run on Microsoft products, meaning if your business currently has little to no current Microsoft infrastructure already in place, you will need to make significant investments in the Microsoft ecosystem to utilize the technology.
3.Can be costly if you don’t qualify for the free version. According to Techwalla, the SQL Server Standard Edition costs $7,171 per processor, and the SQL Server Datacenter edition is $54,990 per processor.
4.Installation and Operation of the server requires Internet Explorer (IE) 4.0
5.Dependency – Once in place, users of Microsoft SQL will become dependent on the Microsoft technology stack and are reliant on the technology firm for any future features or improvements. This typically involves a 2-year cycle wait time for updates.
Enterprise Architecture Overview
Here we are explaining how Appian works as part of an enterprise solution. It includes:
- An overview of the core components of the Appian suite
- How Appian interacts with other software and systems in the enterprise
- How these components work together to provide features for end users, application designers, and administrators
High Level Overview
At a very high level Appian is composed of 6 main software components:
- A front end server hosting the Appian web application
- A set of backend in-memory database engines
- One or more search servers
- One or more relational databases hosting Appian internal and Appian application (business) databases
- A data server to store application patches and user-saved filters
- An internal messaging service that relays messages between different components of Appian
The Appian web application serves requests from users’ browsers or mobile apps and is primarily responsible for all end user, designer, and administrator web interface features.
The Appian engines contain metadata for all the Appian objects created by the designers (groups, process models, rules, constants, knowledge centers, etc) as well as runtime data created by users or processes (process instances, document metadata, etc). Data stored in the engines is accessed and updated by the web application.
The search server provides additional support for application features like viewing recent user activity in the Admin Console.
Appian requires a relational database such as MySQL, SQL Server, or Oracle to store runtime data for Appian interface features like the News feed as well as additional designer metadata not stored in the Appian engines (data types, record types, etc). Appian can connect to additional “business” databases to access and store business data associated with individual applications.
The data server is a next-generation data persistence layer. It provides better performance, more reliability and increased security for application data. Currently, the data server is used to track the design objects added to the application patches and to store the user-saved filters. Over future several releases, more Appian functionality and capabilities will rely on the data server for data persistence.
Appian Architecture
Appian is an enterprise software platform that includes core components that work with other systems (database server, mail server) to provide capabilities and services to users. The following diagram illustrates the components of a typical Appian installation in greater detail:

All core components of the Appian architecture can be configured to support backup/restore and failover for high availability. Since Appian depends on other systems it is equally important to ensure that all associated components are similarly configured for high availability and recovery.Below we are explaining walk through the Appian architecture to explain what each component does and how they interact as well as links to additional documentation resources
Web/Mobile Client
Appian’s end user application interface is supported on all major web browsers and native mobile apps are available for the most popular platforms. The design interface which is used to build applications and the system administration console are also 100% web-based.
All web and mobile clients access Appian using HTTP/S. HTTPS is recommended for production installations. User-uploaded content and third-party extensions are hosted from two independent domains to prevent unintentional or insecure interaction with Appian interfaces. Minimal web browser configuration is required and Appian does not use browser extensions or plugins. Internal-facing Appian sites typically require the use of mobile VPN tools to enable mobile access from commercial cellular networks.
Web Server
As with most web applications Appian installations should use a web server to handle client requests before passing traffic to the application server. A web server can be used to handle static requests (images, css, etc.) which enables that content to be cached by client browsers for improved performance. Multiple web servers can be used with a load balancer. When using HTTPS a web server can remove the SSL overhead from the application server. Some deployments may also use an SSL accelerator (often combined with a load balancer) before traffic reaches the web server to further optimize HTTPS performance.
Requests for non-static content are passed through from the web server to the application server. The connection configuration between these components depends on which web and application server platforms are used. For example:
- Apache web server uses mod_jk to connect to Appian
- IIS web server uses the ISAPI Redirector DLL to connect to Appian
These methods of communication are not Appian-specific but do require Appian-specific configurations to control which types of content are served by each component and other settings.
Application Server
An application server is a multi-threaded execution environment for web applications and provides built-in support for connecting to a wide range of related system components. Appian requires Java 8 or higher.
The application server coordinates most of the interaction between system components and is responsible for a significant portion of Appian’s functionality.
The application server handles end-user web or mobile client requests that are passed through from the web server (including authentication and authorization for those requests). It retrieves and updates data in the Appian engines and the primary and business databases. It manages documents uploaded by users and generated by processes. It executes business rules, runs the activities defined in process models, and communicates with external systems. It can be extended using plug-ins deployed using the OSGi framework.
Because the application server is involved in such a significant amount of activity it is a central source of logging and other information about system usage, health, and performance. It also has a wide range of configuration options, most of which are managed in the custom.properties file or the administration console interface.
Appian Engines
The Appian engines are in-memory, real-time databases based on KDB and the K language. The engines provide extremely fast storage and retrieval of data and also contain low level logic for high volume operations like security and group membership checks.
A default Appian installation has 15 engines: 3 process execution and 3 process analytics engines 6 other individual engines and 3 to support legacy portal. Process execution and analytics can each have up to 32 total engines defined, always in paired sets. Additional execution and analytics engines can be used to load balance high process execution and/or reporting volume across more engines and more engine servers (in a distributed environment).
Each engine serves a unique role in the Appian architecture. The execution and analytics engine come in pairs and are expandable up to 32 pairs of engines:
- Process Execution: Manages process execution and data for associated process models. Also referred to as exec, PX.
- Process Analytics: Stores all relevant information that may be used in a report on a process. Also referred to as analytics, PA.
The following six engines play a significant and active role in current features:
- Content: Stores metadata and security settings for documents and their organizational structures (communities, knowledge centers, and folders). The actual document content is stored on the file system, not in the engine. Also referred to as collaboration, collab, CO.
- Collaboration Statistics: Contains statistics on document usage and storage. Also referred to as collab-stat, CS.
- Portal Notifications: Stores information about system notification settings. Also referred to as notif, notifications, NO.
- Email Notifications: Responsible for generating and sending notifications via email. Also referred to as notif-email, NE.
- Personalization: Stores information about users, groups, group membership, and group types. Also referred to as groups, PE.
- Process Design: Stores all information that pertains to the design of the process models within the application. Also referred to as design, PD.
The following engines support older features in the Apps Portal interface:
- Portal: Stores all information about pages in the Apps Portal interface. Also referred to as PO.
- Channels: Stores information about the portlet types that are displayed on portal pages in the Apps Portal interface. Also referred to as CH.
- Forums: Stores all of the topics and messages posted to discussion forums in the Apps Portal interface. News content in the Tempo interface is not stored in this engine. Also referred to as discussion forums, DF.
Search Server
The search server contains an ElasticSearch server and aggregates data from the rest of the application to support features like tracking historical performance, viewing recent user activity, and analyzing design-time impacts/dependencies. The search server runs as a stand alone java application and multiple search servers can be configured to allow for both data redundancy and high availability.
Relational Database
Appian requires one relational database to be configured as a data source. This database is used to store system metadata like data types and security settings as well as run-time data like News post content.
Additional “secondary” or “business” databases can be used by applications built in Appian to store and retrieve business data specific to those applications. Data from these sources can be used in many places within an application including in processes, on forms, as records, and in reports. Secondary databases may be created as part of an Appian application or may be existing databases that Appian uses.
Database connections are managed using the application server’s JDBC data source connection configuration. These settings specify the database host, credentials, pooling, recovery, and other connection options.
File Storage
The application server and Appian engines are installed on and store run-time content on the file system, although they store data in independent directories and do not use the file system to share data with each other. Shared storage (Windows or NFS) is required when running a distributed environment with multiple application servers or multiple engines different servers.
The application server stores run-time content in the directories under <APPIAN_HOME>/_admin:
accdocs1,accdocs2,accdocsX: Contain documents uploaded by users and generated by processes.logs: Contains all application server logs.mini: Contains data displayed in web content channels in the Apps Portal interface.models: Contains XML files associated with Appian process models.process_notes: Contains data for the process and task notes feature available in the Apps Portal interface.shared: Contains the site-wide keystore used for securing passwords and the encryption and secure credential store services.
The Appian engines store run-time content in the directories under <APPIAN_HOME>/server:
../gw1,../gw2,../gwX: Contain .kdb files that persist in-memory engine state and transactions.archived-processes: Contains .l files representing process instances that have been archived by the process execution engines.logs: Contains all Appian engine logs.msg: Contains message content for discussion forums in the Apps Portal interface.
Default storage locations can be changed using configuration settings and maintenance scripts.
Data Server
The data server is a storage layer designed for Appian platform. It is a standalone application which consists of two data stores:
- A historical store with a single kdb+ database optimized for writes
- A real-time store with potentially multiple kdb+ databases optimized for reads
In the current version, the data server stores application patches and user-saved filters. In future versions of Appian, more functionalities will rely on the data server as a persistence layer.
Mail Server
Appian requires an external SMTP server to send outgoing email including system notifications and email messages sent by process instances. SMTP configuration supports common security features like SSL/TLS and server authentication.
Appian can also be configured to receive email over POP3 or IMAP/S. The application server polls the mail server and routes each incoming message to either start a new process or continue an existing process flow from an event node.
Authentication Services
Appian’s default authentication uses a username/password login form for web browser clients and HTTP Basic for web API clients. User credentials are validated against Appian’s internal account data in the personalization engine. The default configuration also includes features like “remember me” authentication and password complexity/expiration controls.
Other authentication protocols and methods including LDAP/Active Directory and SAML can be configured in the Administration Console.
Integration Services
As an enterprise solution Appian often integrates with external systems in order to display information to users, move data between systems, make decisions in business processes, and more. All of these integration capabilities are managed by the application server and can be extended using OSGi plug-ins.
Appian also has several built-in connectors and connected systems that enable rapid integration with CMIS content management systems, Microsoft Dynamics, Salesforce, SAP, Siebel, and SharePoint. The Appian for SharePoint module provides additional support for exposing Appian data inside SharePoint.
In addition Appian can connect using more general purpose integration methods like JMS, file transfer protocols, and multiple out-of-the-box web services options that can read and write data using process model smart services (SOAP, REST) or from interfaces like a record or report .Appian also simplifies incoming integration by exposing process models as web services.
Internal Messaging Service
The Internal Messaging Service is responsible for relaying data between different components of Appian’s architecture. It is implemented using Apache Kafka which is an open source distributed messaging system with publish-subscribe semantics and Apache Zookeeper which coordinates leader election within the Kafka cluster.Currently the Internal Messaging Service is used as a transaction log for the Engines and the Data Server.
SQL Server Architecture consists of the following.
- Page Architecture
- Database Architecture
- Network Architecture
- Detailed SQL Architecture
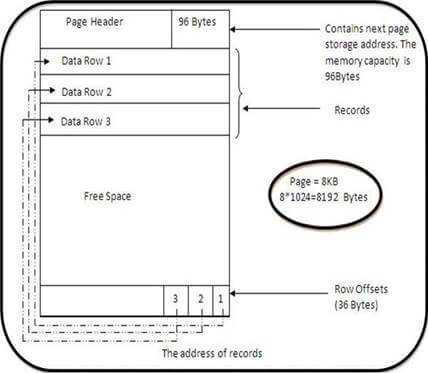
Page Architecture
The data in the database is saved in the least unit, that is, the data page. The size of the data page is 8 KB. Data page consists of a Page Header, Data Row, and Row Offset.
Page Header
It is the header of the data page and is 96 bytes. It holds metadata information about the page, such as Page Type (Data Page, Index Page, Text Page, GAM, IAM, Page Free Space), Page Number, Pointer to next page and previous page, Amount of Free Space, Amount of Space Used, Allocation Id of the object that owns that object.
Data Rows
This stores the actual data which is 8060 Bytes. If data in any row exceeds the limit of 8060 Bytes then the rest of the data is stored in the new page or a series of new pages known as allocation unit and the pointer to that is stored in the header.
Row Offset
It saves the data row’s pointer in the reverse order. The last row in the data page may be the first record in the row offset. It holds the information, that is how far is the specific row is from the header.
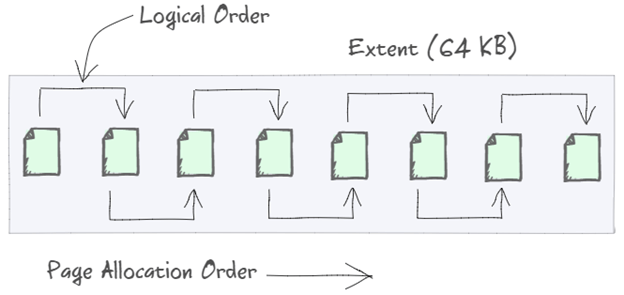
The data in the data file is stored as extents. An extent is a combination of 8 continuous pages of 8KB, that means the size of every extent is 64KB. Now, as discussed earlier, if the data in a row exceeds 8060Bytes in the data page, the rest of the data is stored in the next page and a pointer to that is stored in the header of the previous page. Next may be a page or a combination of pages known as allocation unit.
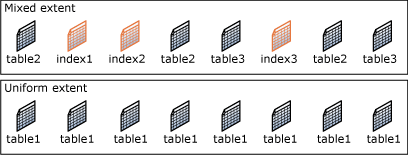
There are two types of extents.
- Uniform Extent – In which the data pages belong to one object.
- Mixed Extent – In which the pages are shared by different objects.
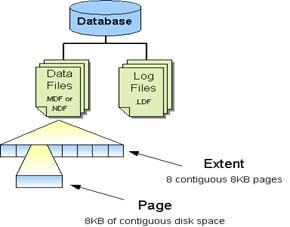
Database Architecture
SQL Server database is a logical collection of data. Data is stored in two sets of files – Data Files and Log Files. An Extent consists of 8 – 8KB continuous pages and in similar manner the data file consists of extents. Log files store all modifications that are made to the database such as DDL, DML operations.
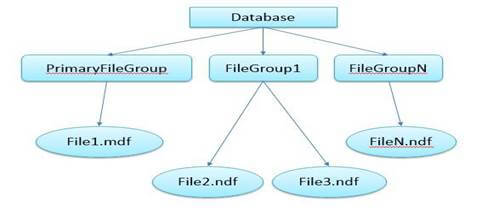
Data Files
When we create a database there are two files created for every database — that is the Data File(.mdf) and Log File(.ldf) and a Primary filegroup (a container) is created in which .mdf (Primary Data File) resides. Log file cannot be contained in a Filegroup. It is always recommended to store the Log File in a different disk separate from data file.
We can create multiple data files, created with .ndf extension and they can be grouped in a secondary filegroup to be able to separate the production data and sort it out.
If we add two secondary data files(.ndf) in a separate filegroup, the SQL Server stores the data in data files (.ndf) in a round robin basis. That is, first extent is saved in the first file and the second in the second file and the third again in the first and so on.The primary data file (.mdf) when created stores additional information as Database configuration, user info, Collation, Recovery Model, roles etc.
Log Files
When we create a database a default file is created to save all the modifications made on the objects in a Log File created with the extension of .ldf. It is always recommended to have a separate disk space for log files as they grow according to the number of transactions.
They should be regularly backed up in order to recover from any failure as they provide point-in-time recovery of the database, helping to restore the database in a consistent state before the failure, by rolling back the uncommitted transactions or rolling forward to the committed transactions.
Log files save all the modifications made by DML and DDL queries on the database objects. Log files initially save all the transactions in the log Files in a log buffer by providing the Log Sequential Number for every Transaction. Before saving (or we should say committing) any data to log files, the log data is saved in the log buffer in the buffer cache of SQL Server. All the committed transaction data (Dirty Log) is saved to the transaction log before the committed data (Dirty Pages) is saved in the data files. This is known as Write Ahead Logging (WAL). We will discuss the entire Transaction Management in the later part as well. So as of now just keep in mind that the Log files save all the transactional logs.
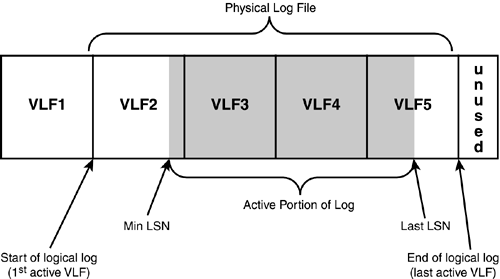
Unlike Data files, log files save data in Virtual Log Files rather than pages. The above diagram clearly represents how the data is saved in the Virtual log File inside a Physical Log File. The transaction Manager assigns an LSN to every transaction to be able to isolate it from other transactions and save the log in the Log Cache. When checkpoint happens it first saves all the committed transaction logs into Log Files and then pushes all the dirty pages to the data files and marks them as Clean.
The process of saving transaction log data prior to pushing dirty pages is known as Write Ahead Logging (WAL). The checkpoint pushes all dirty pages (Pages which are modified in the cache but not yet saved to the disk) to the disk and marks them as clean but does not deallocate the pages from cache.
Lazywriter does the same thing but for a different purpose. It flushes the dirty pages to the disk and deallocates the clean pages in order to provide space in the memory. SQL Serve performs lazy writer when it comes under memory pressure.
Network Architecture
SQL Server uses different protocols for connecting to the SQL Engine and services.
- Shared Memory
It is used to connect the stand alone application where the client is running on the same computer as the server. - TCP/IP
The most commonly used protocol in SQL Server to connect to the services. Default TCP/IP port is 1433. You can use any user defined port as well to connect with the SQL Server. It is recommended to change your default port after installing SQL Server. - Named Pipes
TCP/IP are comparable protocols. Named Pipes are developed for LAN, but it can be inefficient for WAN (Wide Area Network).
Detailed SQL Server Architecture
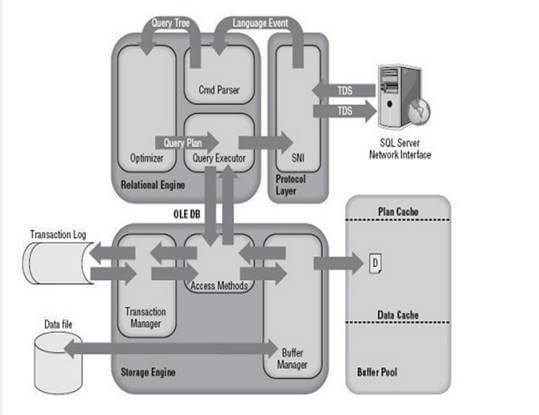
Following is the process which a SQL Query goes through.
- The SQL query is fired at the application end. From there it is converted into TDS (Tabular Data Stream) Packets using ODBC or OLEDB or SNAC (SQL Native Client) or SNI (SQL Server Network Interface). These are data access protocols which are used to access all types of data and grind them into TDS packets to be encapsulated within network packets to be travelled through network protocols from one endpoint to other.
- Once TDS packets reach the server endpoint, the SNI decapsulates those packets into SQL commands.
- The commands are passed through Query Parser or Command Parser and it checks the query for any Syntactical (Syntax) or Semantical (Logical) errors and if any error occurrs it returns the error to the N/W protocol layer.
- If it passes through the command parser, the next step is to generate a query plan. The query optimizer selects a cost effective plan provided to it using Query Tree (It uses certain algorithms to generate different query plans and presents it to the Query Optimizer.
- Query optimizer then selects a cost effective plan and presents the query to Query Executor. To execute a plan Query Executor needs data as well. So it passes the request to the Access Methods which is a collection of codes which provides an interface to retrieve data and present it to Query Executor after valid conversion using OLEDB. It itself does not do this work, rather it asks the buffer manager for the data.
- If the data is there in the Buffer, Access methods fetch those data pages and pass them to the query executor to execute the query. If the query plan is already in the Plan cache the executor uses that plan.
- The work of access method is to check if the query is select or non-select (DML). If the query is non-select the access methods contact Transaction Manager. Transaction Manager has two components,
- Log Manager
Logs the events that will be modifying the data into Log Buffer in Buffer Pool. - Lock Manager
Assigns a lock on that transaction to provide data consistency and isolation.
- Log Manager
- Transaction Manager generates a Log Sequential Number(LSN) for that transaction and records the events that will be modifying the data in Log Buffer and the Transaction will make changes in the buffer cache using only locking mechanism to be isolated from any other transaction who wants to modify the same data. Changes are not directly made to the data pages on the disk.
These modified pages reside in the buffer cache and are known as Dirty Pages, as they are not written to the disk as of yet. Now there is a checkpoint process that is an automatic recurring event in SQL server and runs in the background. When checkpoint happens, it flushes all the dirty pages (Modified Pages) to the disk and marks the pages as clean (pages not modified since last fetch) in the buffer cache, but does not deallocate those pages from cache. Before it does that the Log records are pushed into a Virtual Log File (data page of log file) with the LSN in Transaction Log from Log Buffer. This process of writing to the Log File before writing to the disk is known as Write Ahead Logging.
Lazy Writer, again a background process, also flushes the pages out of the buffer pool to the disk. When the SQL server comes under the memory pressure, lazy writer deallocates the pages which are residing there unused, also the clean pages from the memory, and writes the dirty pages to the disk to be able to make some memory space for other operations.
-SQL Server 2016 Enterprise edition is the premium editions of all in SQL Server 2016. This edition has all the features of SQL Server 2016.
SQL Server 2016 Enterprise edition delivers comprehensive high-end data center capabilities with blazing-fast performance, unlimited virtualization and end-to-end business intelligence — enabling high service levels for mission-critical workloads and end user access to data insights.
SQL Server 2016 Enterprise edition makes leading innovation available to any public cloud like AWS marketplace and Google Cloud Platform ( GCP ).
Cognosys provides hardened images of SQL Server 2016 Enterprise edition on all public cloud ( AWS marketplace and Google Cloud Platform).
Also we offer other editions of SQL server 2016 such as SQL Server 2016 Web edition, SQL Server 2016 Standard edition and SQL Server 2016 Express edition.
SQL Server 2016 Enterprise Edition on Cloud for AWS
Features
New Features of SQL Server 2016
1.SQL Server 2016 Security using Encryption
- In SQL Server 2016, to improve security, data will always be in an encrypted form and the key for its decryption will reside somewhere. So only those users authorized to use your application can use your encrypted database using that key.

- So, if you are using a cloud for your database then now you can feel more relaxed, since the key is in your hand for your encrypted data and no one else can harm your database.

- Sometimes we want to provide access to some sensitive column to only those users authorized for it. This can be done using Dynamic DataMasking, in which we can mask the column depending on user roles if needed.

- In SQL Server 2016 new policies are added for Row-level security in which a user can access rows depending on their roles only. For example, a manager can check a data row depending on his role and employees can access data rows depending on their role.

2.Always On Availability Groups
The following are SQL Server 2016 improvement on Always On Availability Groups:
- SQL Server 2016 has also improved the always on availability group.
- Always on was introduced in SQL Server 2012 for disaster recovery and high availability for databases.
- For example, you can create your availability group (like UK and US) of your existing database that is in one server with other servers using SQL Server 2012 or above by creating a replica of your database.
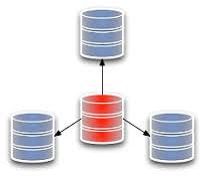
- To provide a connection point for these replica database servers you need to create an Availability group listener. Using this listener a user can connect to a replica database. For example, for the UK group you can create a UK_Listener connection.
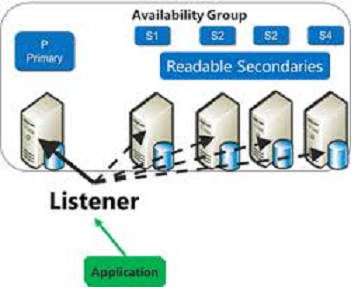
- Another server will also restore your database and if any conflicts occur in the future then these server databases will be highly available for you to recover.
- With SQL Server 2016 you will get support for the Microsoft Distributed Transaction Coordinator (DTC) that allows a client application to include several sources of data.

- SQL Server 2016 has also improved the log of records of all the transactions and database modifications made by each transaction.
- SQL Server 2016 provides better policies for failover. In other words, if one node crashes then another node will be restarted without human intervention.
3.Updates for ColumnStore Indexes
The following shows SQL Server 2016 updates for ColumnStore indexes:
Row-store
Column Store
- With SQL Server 2016, you can run T-SQL constructs in batch mode. In other words, you can send a collection of one or more SQL statements as one unit .

- In SQL Server 2016 more predicates (used in a search condition) and aggregates (like avg, count and so on) are pushed down to the storage engine.
The Storage engine controls database concurrency, manage transactions, locking and logging.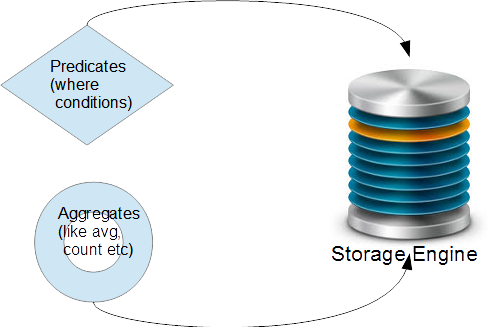
- SQL 2016 has:
- New DMVs that return server-state information.
- New XEvents for handling server systems.
- New performance counters that allow you to measure the current performance.

- SQL Server 2016 provides support for RCSI and snapshot isolation. They are used for improving performance and concurrency in the database.
4.SQL Server 2016 for In-Memory OLTP
In-Memory OLTP (that uses your RAM instead of database disk) will support foreign keys between in-memory tables.
- SQL Server 2016 has increased the size limit of in-memory OLTP from 256 GB to 2TB.
- SQL Server 2016 can also encrypt in-memory tables.
- SQL Server 2016 has added Check constraints, Unique constraints and triggers support for in-memory tables.
5.SQL Server 2016 for DBA Features
- DBA can use a new feature of QueryStore that allows a DBA to track changes and compare execution plans and then determine which plan to use.

- A DBA can keep your archive in a cloud and data on-premise.

6.SQL Server 2016 for DEV features
- SQL Server 2016 provides Native JSON Support as in the following:

- With SQL Server 2016 you can track historical changes in the database.
- SQL Server 2016 has combined Visual Studio 2015 and BI database projects.
-Major Features of SQL Server 2016 Enterprise Edition
- Simplify big data : Take advantage of non-relational data with PolyBase technology built in that allows you to query structured and unstructured data with the simplicity of T-SQL.
- Mission critical intelligent applications : Deliver real-time operational intelligence by combining built-in advanced analytic and in-memory technology without having to move the data or impact end user performance.
- Highest performing data warehouse : Scale to petabytes of data for enterprise-grade relational data warehousing—and integrate with non-relational sources like Hadoop—using scale out, massively parallel processing from Microsoft Analytic Platform System. Support small data marts to large enterprise data warehouses while reducing storage needs with enhanced data compression.
- Mobile BI : Empower business users across the organization with the right insights on any mobile device.
- Easy to use tools : Use the skills you already have, along with familiar tools like Azure Active Directory and SQL Server Management Studio, to manage your database infrastructure across on-premises SQL Server and Microsoft Azure. Apply industry-standard APIs across various platforms and download updated developer tools from Visual Studio to build next-generation web, enterprise, business intelligence and mobile applications.
AWS
Installation Instructions For Windows
Installation Instructions for Windows
Step 1) RDP Connection: To connect to the deployed instance, Please follow Instructions to Connect to Windows instance on AWS Cloud
1) Connect to the virtual machine using following RDP credentials:
- Hostname: PublicDNS / IP of machine
- Port : 3389
Username: To connect to the operating system, use RDP and the username is Administrator.
Password: Please Click here to know how to get password
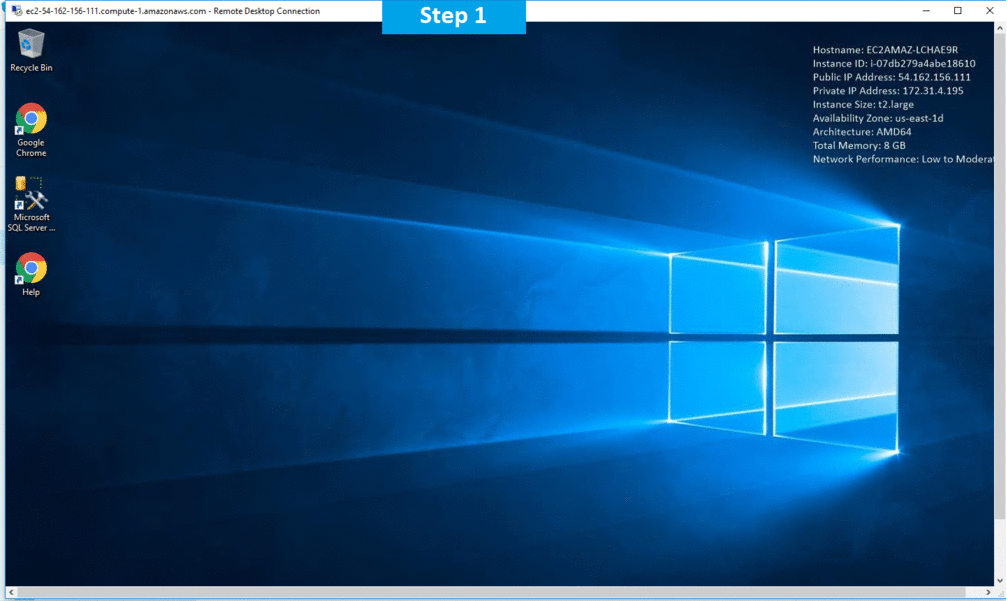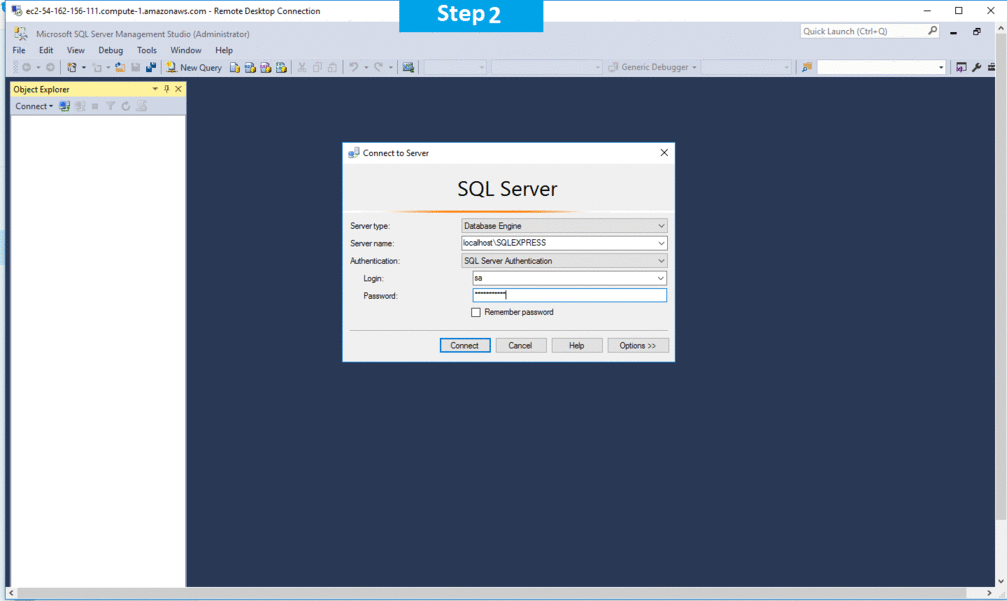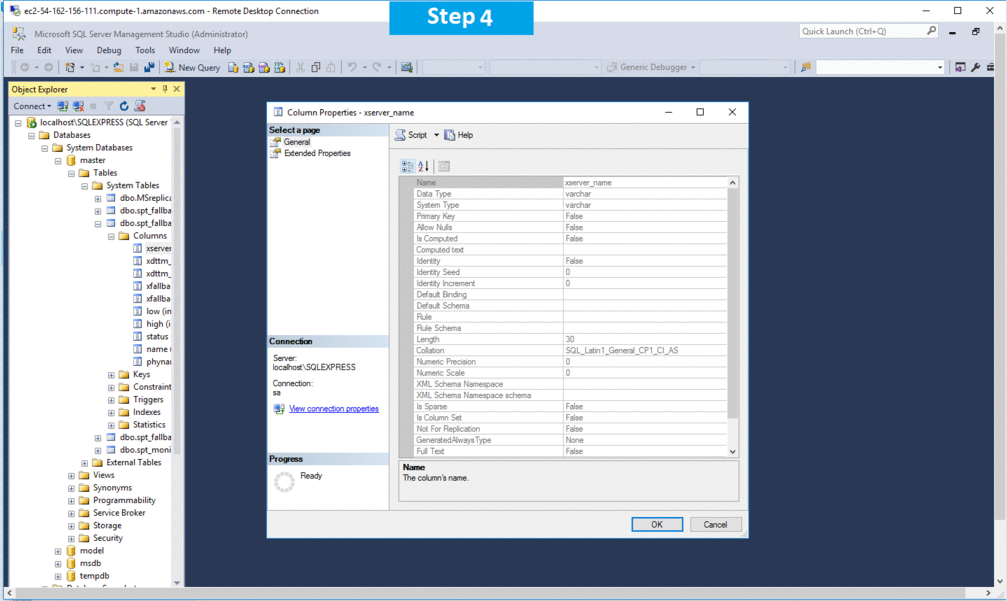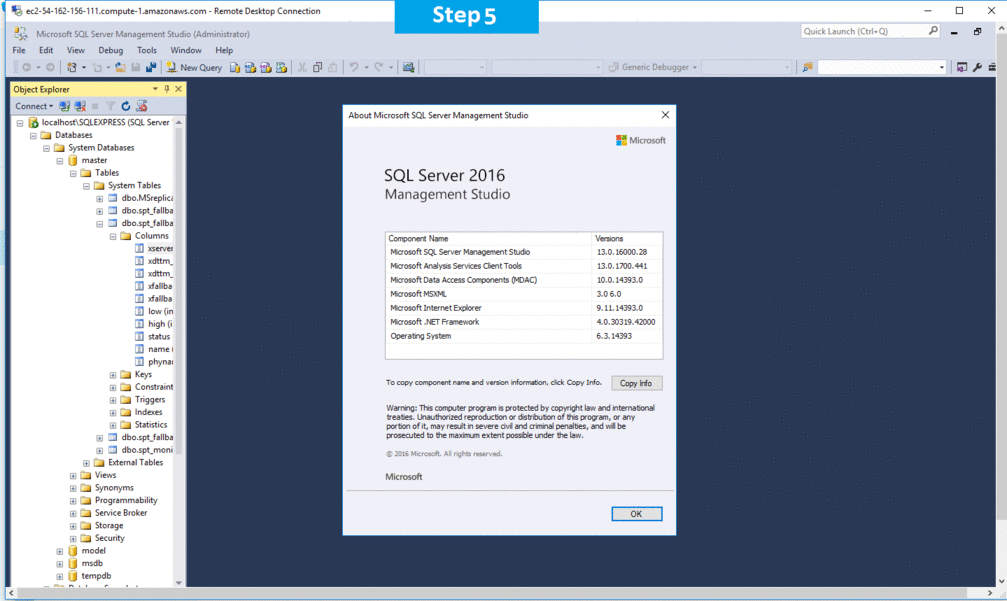
Step 2) SQL Connection: To Connect Microsoft SQL Server Management Studio in Windows server, Please follow Instructions to Connect Microsoft SQL Server Management Studio
Step 3) Database Credentials: You can Login by below SQL Database credentials
SQL UserName : sa || Password : Passw@rd123
Note: You can reset ‘sa’ password by using windows authentication to connect to local SQL instance .Please use localhost in the server name when connecting from inside the RDC
You can Login by below SQL Database credentials
SQL UserName : sa
The below screen appears after successful deployment of the image.
i) Please connect to Remote Desktop as given in step 2
ii) You can use SQL server instance as localhost. The SQL Server instance name to be used is “localhost” Connect to SQL Management Studio with username as sa and password provided in Custom Metadata.
Step 4) Other Information:
1.Default ports:
- Windows Machines: RDP Port – 3389
- sql server port :1433: By default, this is blocked on Public interface for security reasons.
Configure custom inbound and outbound rules using this link
