
1-click AWS Deployment 1-click Azure Deployment 1-click Google Deployment
Overview
HAProxy, which stands for High Availability Proxy, is a popular open source software TCP/HTTP Load Balancer and proxying solution which can be run on Linux, Solaris, and FreeBSD. Its most common use is to improve the performance and reliability of a server environment by distributing the workload across multiple servers (e.g. web, application, database). It is used in many high-profile environments, including: GitHub, Imgur, Instagram, and Twitter.Here, we will provide a general overview of what HAProxy is, basic load-balancing terminology, and examples of how it might be used to improve the performance and reliability of your own server environment.
HAProxy Terminology
There are many terms and concepts that are important when discussing load balancing and proxying. We will go over commonly used terms in the following sub-sections.Before we get into the basic types of load balancing, we will talk about ACLs, backends, and frontends.
Access Control List (ACL)
In relation to load balancing, ACLs are used to test some condition and perform an action (e.g. select a server, or block a request) based on the test result. Use of ACLs allows flexible network traffic forwarding based on a variety of factors like pattern-matching and the number of connections to a backend, for example.
Example of an ACL:
acl url_blog path_beg /blog
This ACL is matched if the path of a user’s request begins with /blog. This would match a request of http://yourdomain.com/blog/blog-entry-1, for example.
Backend
A backend is a set of servers that receives forwarded requests. Backends are defined in the backend section of the HAProxy configuration. In its most basic form, a backend can be defined by:
- which load balance algorithm to use
- a list of servers and ports
A backend can contain one or many servers in it–generally speaking, adding more servers to your backend will increase your potential load capacity by spreading the load over multiple servers. Increase reliability is also achieved through this manner, in case some of your backend servers become unavailable.
Here is an example of a two backend configuration, web-backend and blog-backend with two web servers in each, listening on port 80:
backend web-backend
balance roundrobin
server web1 web1.yourdomain.com:80 check
server web2 web2.yourdomain.com:80 check
backend blog-backend
balance roundrobin
mode http
server blog1 blog1.yourdomain.com:80 check
server blog1 blog1.yourdomain.com:80 check
balance roundrobin line specifies the load balancing algorithm.
mode http specifies that layer 7 proxying will be used.
The check option at the end of the server directives specifies that health checks should be performed on those backend servers.
Frontend
A frontend defines how requests should be forwarded to backends. Frontends are defined in the frontend section of the HAProxy configuration. Their definitions are composed of the following components:
- a set of IP addresses and a port (e.g. 10.1.1.7:80, *:443, etc.)
- ACLs
- use_backend rules, which define which backends to use depending on which ACL conditions are matched, and/or a default_backend rule that handles every other case
A frontend can be configured to various types of network traffic, as explained in the next section.
Types of Load Balancing
Now that we have an understanding of the basic components that are used in load balancing, let’s get into the basic types of load balancing.
No Load Balancing
A simple web application environment with no load balancing might look like the following:

In this example, the user connects directly to your web server, at yourdomain.com and there is no load balancing. If your single web server goes down, the user will no longer be able to access your web server. Additionally, if many users are trying to access your server simultaneously and it is unable to handle the load, they may have a slow experience or they may not be able to connect at all.
Layer 4 Load Balancing
The simplest way to load balance network traffic to multiple servers is to use layer 4 (transport layer) load balancing. Load balancing this way will forward user traffic based on IP range and port (i.e. if a request comes in for http://yourdomain.com/anything, the traffic will be forwarded to the backend that handles all the requests for yourdomain.com on port 80).
Here is a diagram of a simple example of layer 4 load balancing:

The user accesses the load balancer, which forwards the user’s request to the web-backend group of backend servers. Whichever backend server is selected will respond directly to the user’s request. Generally, all of the servers in the web-backend should be serving identical content–otherwise the user might receive inconsistent content. Note that both web servers connect to the same database server.
Layer 7 Load Balancing
Another, more complex way to load balance network traffic is to use layer 7 (application layer) load balancing. Using layer 7 allows the load balancer to forward requests to different backend servers based on the content of the user’s request. This mode of load balancing allows you to run multiple web application servers under the same domain and port.
Here is a diagram of a simple example of layer 7 load balancing:

In this example, if a user requests yourdomain.com/blog, they are forwarded to the blog backend, which is a set of servers that run a blog application. Other requests are forwarded to web-backend, which might be running another application. Both backends use the same database server, in this example.
A snippet of the example frontend configuration would look like this:
frontend http
bind *:80
mode http
acl url_blog path_beg /blog
use_backend blog-backend if url_blog
default_backend web-backend
This configures a frontend named http, which handles all incoming traffic on port 80.
acl url_blog path_beg /blog matches a request if the path of the user’s request begins with /blog.
use_backend blog-backend if url_blog uses the ACL to proxy the traffic to blog-backend.
default_backend web-backend specifies that all other traffic will be forwarded to web-backend.
Load Balancing Algorithms
The load balancing algorithm that is used determines which server, in a backend, will be selected when load balancing. HAProxy offers several options for algorithms. In addition to the load balancing algorithm, servers can be assigned a weight parameter to manipulate how frequently the server is selected, compared to other servers.
Because HAProxy provides so many load balancing algorithms, we will only describe a few of them here.
A few of the commonly used algorithms are as follows:
roundrobin
Round Robin selects servers in turns. This is the default algorithm.
leastconn
Selects the server with the least number of connections–it is recommended for longer sessions. Servers in the same backend are also rotated in a round-robin fashion.
source
This selects which server to use based on a hash of the source IP i.e. your user’s IP address. This is one method to ensure that a user will connect to the same server.
Sticky Sessions
Some applications require that a user continues to connect to the same backend server. This persistence is achieved through sticky sessions, using the appsession parameter in the backend that requires it.
Health Check
HAProxy uses health checks to determine if a backend server is available to process requests. This avoids having to manually remove a server from the backend if it becomes unavailable. The default health check is to try to establish a TCP connection to the server i.e. it checks if the backend server is listening on the configured IP address and port.
If a server fails a health check, and therefore is unable to serve requests, it is automatically disabled in the backend i.e. traffic will not be forwarded to it until it becomes healthy again. If all servers in a backend fail, the service will become unavailable until at least one of those backend servers becomes healthy again.
For certain types of backends, like database servers in certain situations, the default health check is insufficient to determine whether a server is still healthy.
Other Solutions
If you feel like HAProxy might be too complex for your needs, the following solutions may be a better fit:
-
Linux Virtual Servers (LVS) – A simple, fast layer 4 load balancer included in many Linux distributions
-
Nginx – A fast and reliable web server that can also be used for proxy and load-balancing purposes. Nginx is often used in conjunction with HAProxy for its caching and compression capabilities
High Availability
The layer 4 and 7 load balancing setups described before both use a load balancer to direct traffic to one of many backend servers. However, your load balancer is a single point of failure in these setups; if it goes down or gets overwhelmed with requests, it can cause high latency or downtime for your service.A high availability (HA) setup is an infrastructure without a single point of failure. It prevents a single server failure from being a downtime event by adding redundancy to every layer of your architecture. A load balancer facilitates redundancy for the backend layer (web/app servers), but for a true high availability setup, you need to have redundant load balancers as well.
Here is a diagram of a basic high availability setup:

In this example, you have multiple load balancers (one active and one or more passive) behind a static IP address that can be remapped from one server to another. When a user accesses your website, the request goes through the external IP address to the active load balancer. If that load balancer fails, your failover mechanism will detect it and automatically reassign the IP address to one of the passive servers. There are a number of different ways to implement an active/passive HA setup
MySQL Load Balancing with HAProxy
A front-end application that relies on a database backend can easily over-saturate the database with too many concurrent running connections. HAProxy provides queuing and throttling of connections towards one or more MySQL Servers and prevents a single server from becoming overloaded with too many requests. All clients connect to the HAProxy instance, and the reverse proxy forwards the connection to one of the available MySQL Servers based on the load-balancing algorithm used.
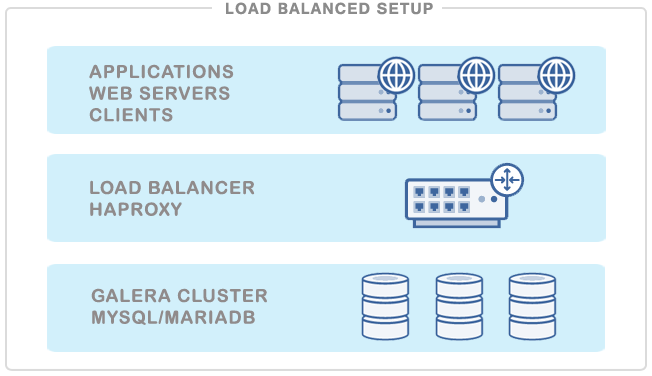
One possible setup is to install an HAProxy on each web server (or application server making requests on the database). This works fine if there are only a few web servers, so as the load introduced by the health checks is kept in check. The web server would connect to the local HAProxy (e.g. making a mysql connection on 127.0.0.1:3306), and can access all the database servers. The Web and HAProxy together forms a working unit, so the web server will not work if the HAProxy is not available.
With HAProxy in the load balancer tier, you will have following advantages:
- All applications access the cluster via one single IP address or hostname. The topology of the database cluster is masked behind HAProxy.
- MySQL connections are load-balanced between available DB nodes.
- It is possible to add or remove database nodes without any changes to the applications.
- Once the maximum number of database connections (in MySQL) is reached, HAProxy queues additional new connections. This is a neat way of throttling database connection requests and achieves overload protection.
ClusterControl support HAProxy deployment right from the UI and by default it supports three load-balancing algorithms – roundrobin, leastconn or source. We recommend users to have HAProxy in between clients and a pool of database servers, especially for Galera Cluster or MySQL Cluster where the backends are being treated equally.
3. Health Checks for MySQL
It is possible to have HAProxy check that a server is up by just making a connection to the MySQL port (usually 3306) however this is not good enough. The instance might be up, but the underlying storage engine might not be working as it should be. There are specific checks need to be passed, depending on whether the clustering type is Galera, MySQL Replication or MySQL Cluster.
3.1. Health Check Script
The best way to perform MySQL health check is by using a custom shell script which determines whether a MySQL server is available by carefully examining its internal state which depends on the clustering solution used. By default, ClusterControl provides its own version of health check script called mysqlchk, resides on each MySQL server in the load balancing set and has ability to return an HTTP response status and/or standard output (stdout) which is useful for TCP health check.
3.1.1. mysqlchk for Galera Cluster
If the backend MySQL server is healthy, then the script will return a simple HTTP 200 OK status code with exit status 0. Else, the script will return 503 Service unavailable and exit status 1. Using xinetd is the simplest way to get the health check script executed by making it daemonize and listen to a custom port (default is 9200). HAProxy will then connect to this port and request for a health check output. If the health check method is httpchk, HAProxy will look for the HTTP response code and if the method is tcp-check, it will look for the expect string (as shown in section 3.2.3).
The following flowchart illustrates the process to report the health of a Galera node for multi-master setup:
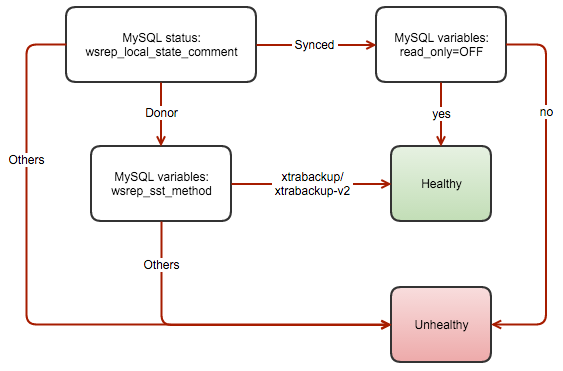
The template file is located at /usr/share/cmon/templates/mysqlchk.galera on ClusterControl server. This mysqlchk script is automatically installed by ClusterControl on each Galera node participating in the load balancing set.
3.1.2. mysqlchk for MySQL Replication
This script is based on the standard mysqlchk script but tailored to monitor MySQL Replication backend servers correctly. The template is available at this Github repository, and you can use it by replacing the default template located /usr/share/cmon/templates/mysqlchk.mysql before the HAProxy deployment begins. It’s similar with mysqlchk for Galera Cluster where xinetd is required to daemonize the health check script.
The script detects the MySQL Replication role based on the following flow chart:
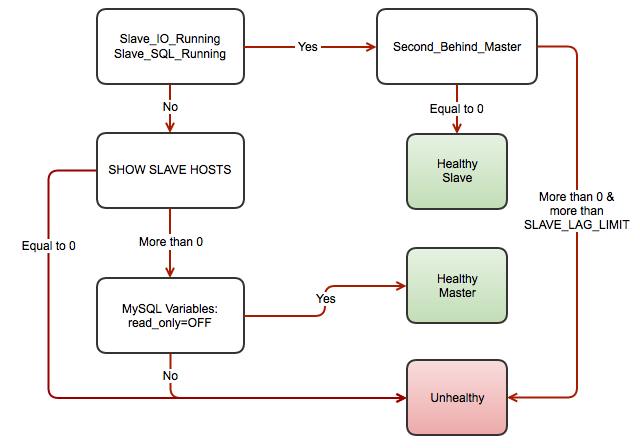
Setting up HAProxy for MySQL Replication requires two different HAProxy listeners e.g, port 3307 for writes to the master and port 3308 for reads to all available slaves (including master).
3.1.3. mysqlchk-iptables for Galera Cluster
A background script that checks the availability of a Galera node, and adds a redirection port using iptables if the Galera node is healthy (instead of returning HTTP response). This allows other TCP-load balancers with limited health check capabilities to monitor the backend Galera nodes correctly.
Other than HAProxy, you can now use your favorite reverse proxy to load balance requests across Galera nodes, namely:
- nginx 1.9 (–with-stream)
- keepalived
- IPVS
- distributor
- balance
- pen
This health check script is out of the scope of this tutorial since it built for TCP-load balancers (other than HAProxy) with limited health check capabilities to monitor the backend Galera nodes correctly. You can watch it in action in the following screencast:
3.2. Health Check Methods
HAProxy determines if a server is available for request routing by performing so called health checks. HAProxy supports several backend health check methods usable to MySQL through the following options:
- mysql-check
- tcp-check
- httpchk
3.2.1. mysql-check
The check consists of sending two MySQL packets, one Client Authentication packet, and one QUIT packet, to correctly close the MySQL session. HAProxy then parses the MySQL Handshake Initialisation packet and/or Error packet. It is a basic but useful test which does not produce error or aborted connect on the server. However, it requires adding an authorization in the MySQL table, like this:
|
1
2
3
|
USE mysql;INSERT INTO user (Host,User) values ('<ip_of_haproxy>','<username>');FLUSH PRIVILEGES; |
Take note that this does not check database presence nor database consistency. To do this, we must use an external check (via xinetd) which is explained in the next section.
3.2.2. tcp-check
By default, if “check” is set, the server is considered available when it’s able to accept periodic TCP connections. This is not robust enough for a database backend, since the database server might be able to respond to connection requests while being in a non-operational state. The instance might be up, but the underlying storage engine might not be working properly. Also, there are specific checks that need to be done, depending on whether the clustering type is Galera or MySQL Cluster (NDB).
mysqlchk script provided by ClusterControl supports returning HTTP status code and standard output (stdout). By utilizing the stdout in xinetd, we can extend the tcp-check capability to make it more accurate with the Galera or MySQL Replication node status. The following example configuration shows the usability of it:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
listen haproxy_192.168.55.110_3307 bind *:3307 mode tcp timeout client 10800s timeout server 10800s balance leastconn option tcp-check tcp-check expect string is\ running. option allbackups default-server port 9200 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100 server galera1 192.168.55.111:3306 check server galera2 192.168.55.112:3306 check server galera3 192.168.55.113:3306 check |
The above configuration lines tell HAProxy to perform health checks using TCP send/expect sequence. It connects to port 9200 of the database and expect for string that contains “is\ running” (backslash is used to escape whitespace). To verify the mysqlchk output through xinetd port 9200, perform telnet to the database node on HAProxy node:
|
1
2
3
4
5
6
7
8
9
10
11
|
$ telnet 192.168.55.111 9200Trying 192.168.55.171...Connected to 192.168.55.171.Escape character is '^]'.HTTP/1.1 200 OKContent-Type: text/htmlContent-Length: 43<html><body>MySQL is running.</body></html>Connection closed by foreign host. |
You can use the similar configuration for MySQL Replication, where the expect string for master is “MySQL Master is running”. For more details on an example deployment of HAProxy as MySQL Replication load balancer, please read this blog.
ClusterControl defaults to use httpchk as described in the next section.
3.2.3. httpchk
Option httpchk uses HTTP protocol to check on the servers health. This is common if you want to load balance an HTTP service, where HAProxy ensures the backend returns specific HTTP response codes before routing the incoming connections. This option does not necessarily require an HTTP backend, it also works with plain TCP backends. Using httpchk is the preferred option whenever possible since it utilizes less resources with stateless HTTP connection.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
listen haproxy_192.168.55.110_3307 bind *:3307 mode tcp timeout client 10800s timeout server 10800s balance leastconn option httpchk option allbackups default-server port 9200 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100 server galera1 192.168.55.111:3306 check server galera2 192.168.55.112:3306 check server galera3 192.168.55.113:3306 check |
The example above tells us that HAProxy will connect to port 9200, where xinetd is listening on the database servers. HAProxy will look for an expected HTTP response code. The mysqlchk script will return either ‘HTTP 200 OK’ if the server is healthy or otherwise ‘HTTP 503 Service not available’.
4. Failure Detection and Failover
When a database node fails, the database connections that have been opened on that node will also fail. It is important that HAProxy does not redirect new connection requests to the failed node.
There are several user defined parameters that determine how fast HAProxy will be able to detect that a server is not available. The following is the example HAProxy configuration deployed by ClusterControl located at /etc/haproxy/haproxy.cfg:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
listen haproxy_192.168.55.110_3307 bind *:3307 mode tcp timeout client 10800s timeout server 10800s balance leastconn option httpchk option allbackups default-server port 9200 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100 server galera1 192.168.55.111:3306 check server galera2 192.168.55.112:3306 check server galera3 192.168.55.113:3306 check |
Quick explanation for each line above:
- listen: Listen section defines a complete proxy with its frontend and backend parts combined in one section. It is generally useful for TCP-only traffic. Specify the HAproxy instance name next to it. The next line describing the section must be indented.
- bind: Bind to all IP addresses on this host on port 3307. Your clients will have to connect to the port defined in this line.
- mode: Protocol of the instance. For MySQL, the instance should work in pure TCP mode. A full-duplex connection will be established between clients and servers, and no layer 7 examination will be performed.
- timeout client: Maximum inactivity time in the client side. It’s recommended to keep the same value with timeout server for predictability.
- timeout server: Maximum inactivity time in the server side. It’s recommended to keep the same value with timeout client for predictability.
- balance: Load balancing algorithm. ClusterControl is able to deploy leastconn, roundrobin and source, though you can customize the configuration at a later stage. Using leastconn is the preferred option so that the database server with the lowest number of connections receives the connection. If the database servers have the same number of connections, then roundrobin is performed to ensure that all servers are used.
- option httpchk: Perform HTTP-based health check instead. ClusterControl configures an xinetd script on each backend server in the load balancing set which returns HTTP response code.
- option allbackups: The load balancing will be performed among all backup servers when all normal ones are unavailable. This option is suitable if the MySQL server is configured as backup, as explained in the Troubleshooting & Workaround section of this tutorial.
- default-server: Default options for the backend servers listed under server option.
- port: The backend health check port. ClusterControl configures an xinetd process listening on port 9200 on each of the database node running a custom health check script.
- inter: The interval between health checks for a server that is “up”, transitionally “up or down” or not yet checked is 2 seconds.
- downinter: The down interval is 5 seconds when the server is 100% down or unreachable.
- rise: The server will be considered available after 3 consecutive successful health checks.
- fall: The server will be considered down/unavailable after 2 consecutive unsuccessful health checks.
- slowstart: In 60 seconds, the number of connections accepted by the server will grow from 1 to 100% of the usual dynamic limit after it gets back online.
- maxconn: HAProxy will stop accepting connections when the number of connection is 64.
- maxqueue: The maximal number of connections which will wait in the queue for this server. If this limit is reached, next requests will be redispatched to other servers instead of indefinitely waiting to be served.
- weight: In Galera, all nodes usually treated equally. So setting it to 100 is a good start.
- server: Define the backend server name, IP address, port and server’s options. We enabled health check by using the check option on each of the server. The rest option are the same as under default-server.
From the above configurations, the backend MySQL server fails at health checks when:
- HAProxy was unable to connect to port 9200 of the MySQL server
- If 9200 is connected, the HTTP response code sent by MySQL server returns other than HTTP/1.1 200 OK (option httpchk)
Whereby, the downtime and uptime chronology would be:
- Every 2 seconds, HAProxy performs health check on port 9200 of the backend server (port 9200 inter 2s).
- If the health check fails, the fall count starts and it will check for the next failure. After 5 seconds, if the second try still fails, HAProxy will mark the MySQL server as down (downinter 5s fall 2).
- The MySQL server is automatically excluded from the list of available servers.
- Once the MySQL server gets back online, if the health check succeeds, the rise count starts and it will check if the next consecutive attempt is succeeded. If the count reaches 3, the server will be marked as available (rise 3).
- The MySQL server is automatically included into the list of available servers.
- The MySQL server starts to accept the connections gradually for 60 seconds (slowstart 60s).
- The MySQL server is up and fully operational.
5. Read/Write Splitting with HAProxy
HAProxy as MySQL load balancer works similarly to a TCP forwarder, which operates in the transport layer of TCP/IP model. It does not understand the MySQL queries (which operates in the higher layer) that it distributes to the backend MySQL servers. Due to this, HAProxy is popular among multi-master replication setups like Galera Cluster and MySQL Cluster, where all backend MySQL servers are treated equally. All MySQL servers are able to handle the forwarded reads/writes. Operating in transport layer also consumes less overhead compared to database-aware load balancer/reverse proxy like MaxScale or ProxySQL.
In spite of that, it does not mean that HAProxy is not applicable for other non-multi-master setups especially master-slave replication. In MySQL Replication, things get a little bit complicated. Writes must be forwarded only to a master, while reads can be the forwarded to all slaves (or master) as long as the slave does not lag behind. Updating more than one master in a replication setup can result in data inconsistency and cause replication to break.
To make HAProxy capable of handling reads and writes separately, one must:
- Configure health checks for MySQL Replication. The health check script must be able to:
- Report the replication role (master, slave or none)
- Report the slave lag (if slave)
- Must be accessible by HAProxy (configured via xinetd or forwarding port)
- Create two HAProxy listeners, one for read and one for write:
- Read listener – forward to all slaves (or master) to handle reads.
- Write listener – forward writes to a single master.
- Instruct your application to send reads/writes to the respective listener:
- Build/Modify your application to have ability to send reads and writes to the respective listeners
- Use application connector which supports built-in read/write splitting. If you are using Java, you can use Connecter/J. For PHP, you can use php-mysqlnd for master-slave. This will minimize the changes on the application side.
6. Integration with ClusterControl
ClusterControl integrates with HAProxy to ease up deployment and management of the load balancer in combination with a clustered MySQL backend like Galera or MySQL NDB Cluster. It is also possible to add an existing/already deployed HAProxy instance into ClusterControl, so you can monitor and manage it directly from ClusterControl UI together with the database nodes.
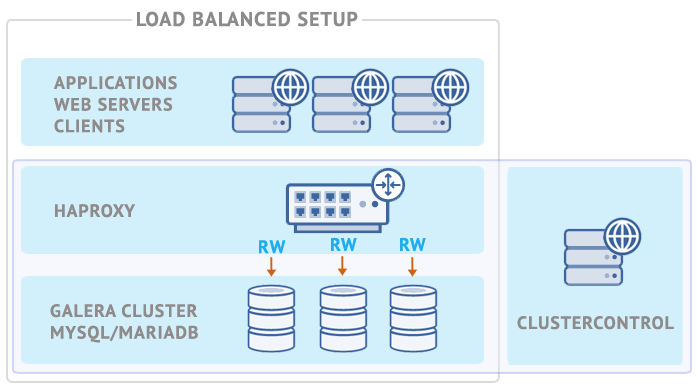
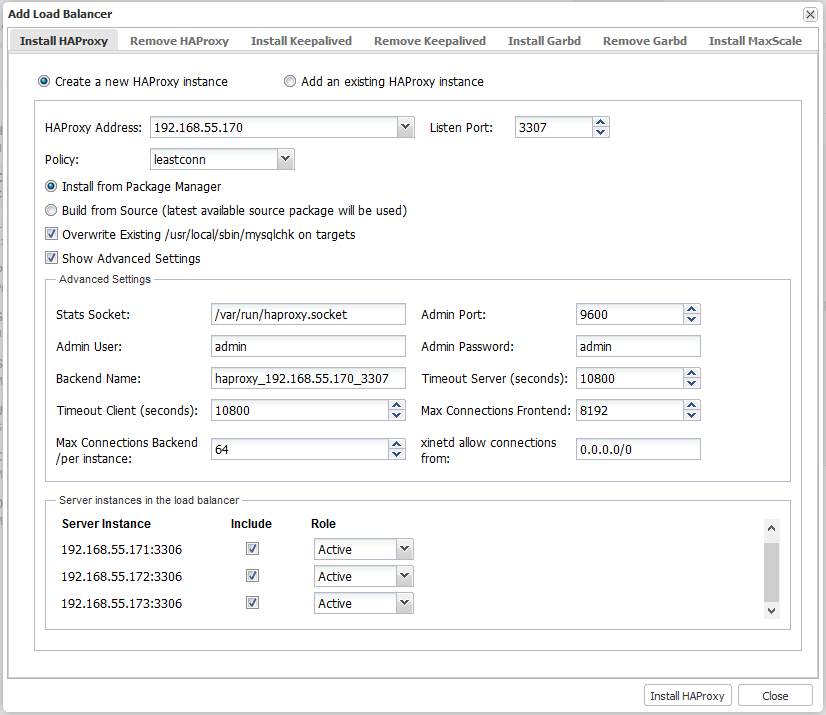
To install, you just need to go to ClusterControl > Manage > Load Balancer > Install HAProxy tab and enter the required information:
- HAProxy Address: IP address or hostname of HAProxy node. ClusterControl must be able to connect via passwordless SSH.
- Listen Port: Port that HAProxy instance will listen to. This port will be used to connect to the load-balanced MySQL connections.
- Policy: Load balancing algorithm. Supported values are:
- leastconn – The server with the lowest number of connections receives the connection.
- roundrobin – Each server is used in turns, according to their weights.
- source – The client IP address is hashed and divided by the total weight, so it will always reach the same server as long as no server goes down or up.
- Install from Package Manager: If Redhat based, install via yum package manager. For Debian-based, apt-get command will be used.
- Build from Source (latest available source package will be used:
- ClusterControl will compile the latest available source package downloaded from haproxy site.
- This option is only required if you intend to use the latest version of HAProxy or if you are having problem with the package manager of your OS distribution. Some older OS versions do not have HAProxy in their package repositories.
- Overwrite Existing /usr/local/sbin/mysqlchk on targets: If the mysqlchk script is already there, overwrite it for this deployment. If you have adjusted the script to suit your needs, you might need to uncheck this.
- Show Advanced Settings:
- Stats Socket: UNIX socket file location for various statistics outputs. Default is /var/run/haproxy.socket and it’s recommended not to change this.
- Admin Port: Port for HAProxy admin-level statistic page. Default is 9600.
- Admin User: Admin user when connecting to the statistic page.
- Admin Password: Password for Admin User
- Backend Name: The listener name for backend. No whitespace.
- Timeout Server (seconds): Maximum inactivity time in the server side.
- Timeout Client (seconds): Maximum inactivity time in the client side.
- Max Connections Frontend: Maximum per-process number of concurrent connections for the frontend.
- Max Connection Backend per instance: Limit the number of connection that can be made from HAProxy to each MySQL Server. Connections exceeding this value will be queued by HAProxy. A best practice is to set it to less than the MySQL’s max_connections to prevent connections flooding.
- xinetd allow connections from: Only allow this network to connect to the health check script on MySQL server via xinetd service.
- Server Instances: List of MySQL servers in the cluster.
- Include: Include the server in the load balancing set.
- Role: Choose whether the node is Active or Backup. In Backup mode, the server will is only used in load balancing when all other Active servers are unavailable.
Once the dialog is filled up, click on ‘Install HAProxy’ button to trigger the deployment job:
ClusterControl will perform the following tasks when the deployment job is triggered:
- Installs helper packages
- Tunes the TCP stack of the instance
- Copies and configures mysqlchk script (from template) on every Galera node
- Installs and configures xinetd at /etc/xinetd.d/mysqlchk
- Registers HAProxy node into ClusterControl
You can monitor the deployment progress under ClusterControl > Logs > Jobs, similar to example below:

By default, the HAProxy server will listen on port 3307 for connections. In this example, the HAProxy host IP address is 192.168.55.170. You can connect your applications to 192.168.55.170:3307 and requests will be load balanced on the backend MySQL Servers.
Do not forget to GRANT access from the HAProxy server to the MySQL Servers, because the MySQL Servers will see the HAProxy making the connections, not the Application server(s) itself. In the example above, issue on the MySQL Servers the access rights you wish:
|
1
|
mysql> GRANT ALL PRIVILEGES ON mydb.* TO 'appuser'@'192.168.55.170' IDENTIFIED BY 'password'; |
The HAProxy process will be managed by ClusterControl, and is automatically restarted if it fails.
7. HAProxy Redundancy with Keepalived
Since all applications will be depending on HAProxy to connect to an available database node, to avoid a single point of failure with your HAProxy, one would set up two identical HAProxy instances (one active and one standby) and use Keepalived to run VRRP between them. VRRP provides a virtual IP address to the active HAProxy, and transfers the Virtual IP to the standby HAProxy in case of failure. This is seamless because the two HAProxy instances need no shared state.
By adding Keepalived into the picture, our infrastructure will now look something like this:
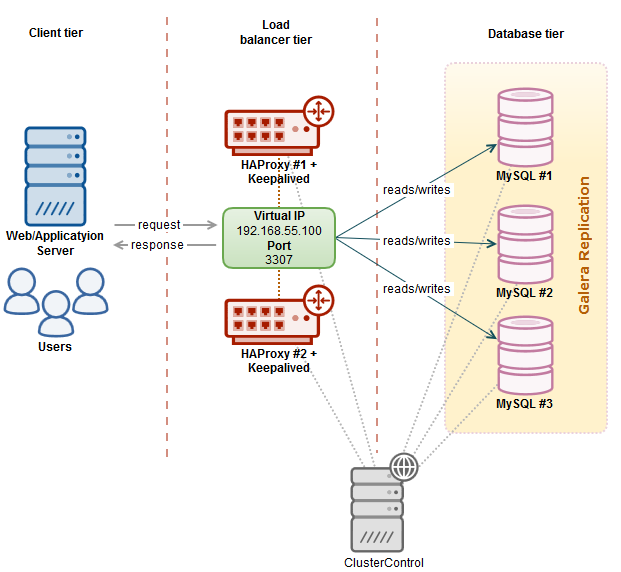
In this example, we are using two nodes to act as the load balancer with IP address failover in front of our database cluster. virtual IP (VIP) address will be floating around between HAProxy #1 (master) and HAProxy #2 (backup). When HAProxy #1 goes down, the VIP will be taking over by HAProxy #2 and once the HAProxy #1 up again, the VIP will be failback to HAProxy #1 since it hold the higher priority number. The failover and failback process is automatic, controlled by Keepalived.
You need to have at least two HAProxy instances in order to install Keepalived. Use “Install HAProxy” to install another HAProxy instance and then go to ClusterControl > Manage > Load Balancer > Install Keepalived to install or add existing Keepalived instance, as shown in the following screenshot:
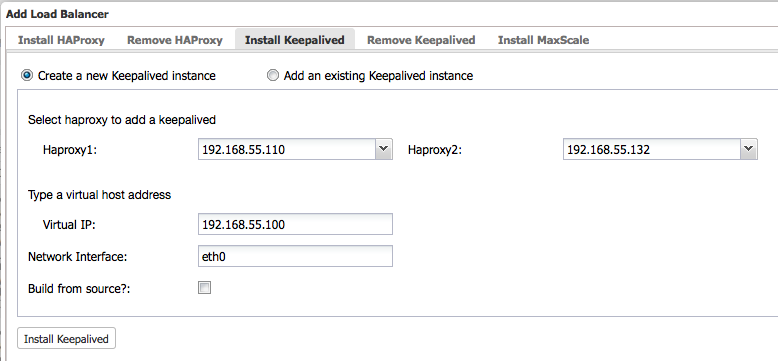
Take note that your network environment supports VRRP (IP protocol 112) for health check communication between two nodes. It’s also possible to let Keepalived run in non-multicast environment by configuring unicast, which will be used by default by ClusterControl if Keepalived installed is version 1.2.8 and later.
8. HAProxy Statistics
Other than deployment and management, ClusterControl also provides insight into HAProxy statistics from the UI. From ClusterControl, you can access the statistics page at ClusterControl > Nodes > choose the HAProxy node similar to screenshot below:
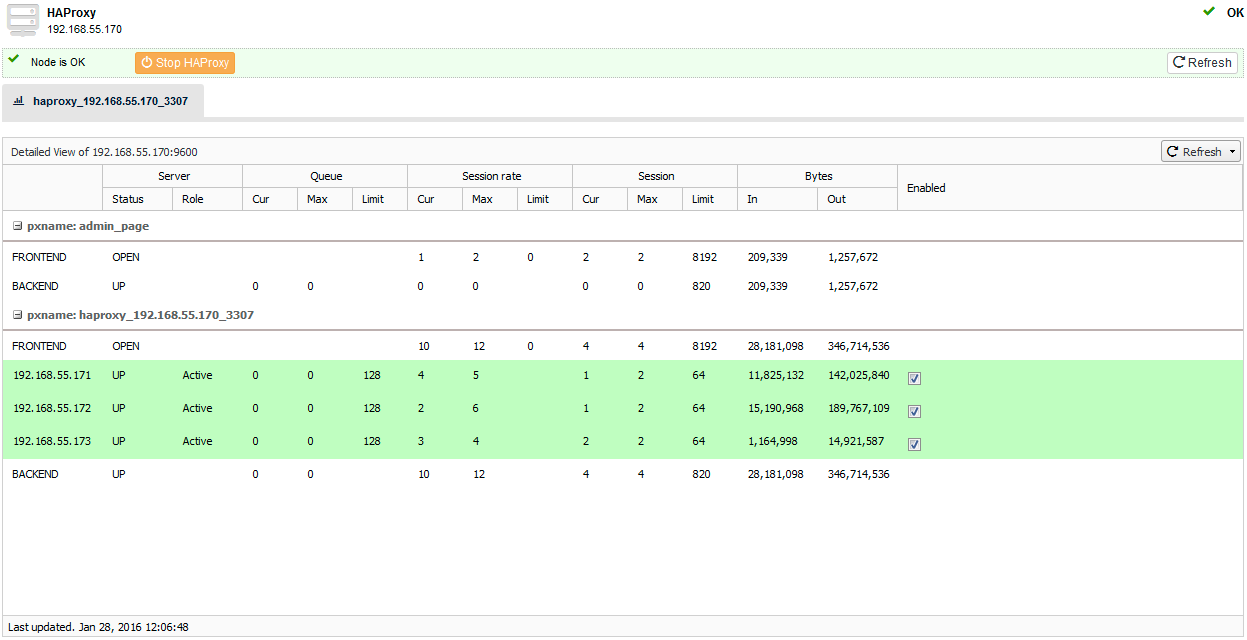
You can enable/disable a server from the load balancing by ticking/unticking the checkbox button under “Enabled” column. This is very useful when you want your application to intentionally skip connecting to a server e.g., for maintenance or for testing and validating new configuration parameters or optimized queries.
It’s also possible to access the default HAProxy statistic page by connecting to port 9600 on the HAProxy node. Following screenshot shows the example when connecting to http://[HAProxy_node_IP_address]:9600/ with default username and password “admin”:
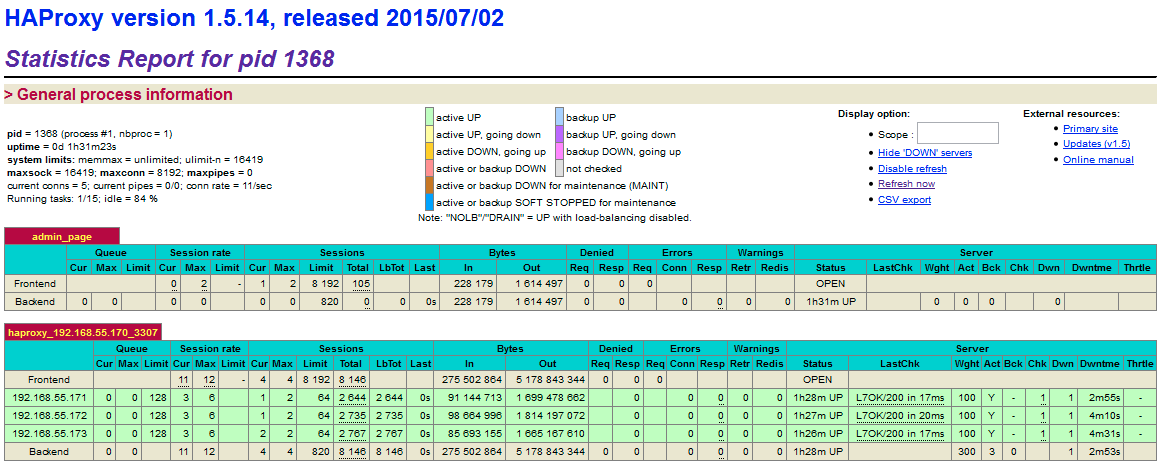
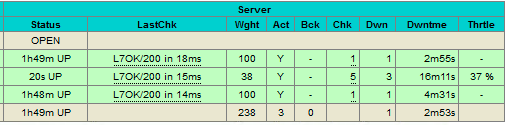
Based on the table legend, the green rows indicate that the servers are available, while red indicates down. When a server becomes available, you should notice the throttling part (last column) where “slowstart 60s” kicks in. This server will receive gradual connections where the weight is dynamically adjusted for 60 seconds before it reaches the expected weight (weight 100):
9. Troubleshooting & Workaround
This section provides some guidance on some common issues when configuring MySQL with HAProxy, Keepalived and ClusterControl.
9.1. MySQL Deadlocks in Galera
Galera cluster has known limitations, one of them is that it uses cluster-wide optimistic locking. This may cause some transactions to rollback. With an increasing number of writeable masters, the transaction rollback rate may increase, especially if there is write contention on the same dataset. It is of course possible to retry the transaction and perhaps it will COMMIT in the retries, but this will add to the transaction latency. However, some designs are deadlock prone, e.g sequence tables.
The solution is to create another listener for single-node read/write and tell your application to send the problematic queries to the respective listener. Following example shows snippets of HAProxy listeners for multi-node reads/writes on port 3307 and single-node reads/writes on port 3308:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
listen haproxy_192.168.55.110_3307_multi bind *:3307 mode tcp timeout client 10800s timeout server 10800s balance leastconn option httpchk option allbackups default-server port 9200 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100 server galera1 192.168.55.111:3306 check server galera2 192.168.55.112:3306 check server galera3 192.168.55.113:3306 checklisten haproxy_192.168.55.110_3308_single bind *:3308 mode tcp timeout client 10800s timeout server 10800s balance leastconn option httpchk option allbackups default-server port 9200 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100 server galera1 192.168.55.111:3306 check server galera2 192.168.55.112:3306 check backup server galera3 192.168.55.113:3306 check backup |
9.2. MySQL Server has gone away
This is usually caused when HAProxy has closed the connection due to timeout or the connection is closed on the server side. Sometimes, you could see this when the server is restarting or the connection has reached one of the following timeouts (following defaults are for MySQL variables deployed by ClusterControl):
- connect_timeout – Default is 10s
- deadlock_timeout_long – Default is 50000000s
- deadlock_timeout_short – Default is 10000s
- delayed_insert_timeout – Default is 300s
- innodb_lock_wait_timeout – Default is 50s
- interactive_timeout – Default is 28800s
- lock_wait_timeout – Default is 31536000s
- net_read_timeout – Default is 30s
- net_write_timeout – Default is 60s
- slave_net_timeout – Default is 3600s
- thread_pool_idle_timeout – Default is 60s
- wait_timeout – 28800s
Our recommendation is to configure the net_read_timeout and net_write_timeout value with the same value as for timeout client and timeout server in HAProxy configuration file.
9.3. Non-uniform Hardware
If you have non-uniform hardware, setting up weight for each server might help to balance the server’s load. All servers will receive a load proportional to their weight relative to the sum of all weights, so the higher the weight, the higher the load. It is recommended to start with values which can both grow and shrink, for instance between 10 and 100 to leave enough room above and below for later adjustments.
Galera replication performance is determined by the slowest node in the cluster. Let’s say in a three-node cluster, the third node is introduced with half of the capacity of the other two nodes. It’s a good practice to reduce the weight for that particular server by half so it gets fair amount of connections and doesn’t drag down the other members to run in full capacity:
|
1
2
3
4
5
|
...default-server port 9200 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100server galera1 192.168.55.111:3306 checkserver galera2 192.168.55.112:3306 checkserver galera3 192.168.55.113:3306 check weight 50 |
-HAProxy is free, open source software that provides a high availability load balancer and proxy server for TCP and HTTP-based applications that spreads requests across multiple servers.It is written in C and has a reputation for being fast and efficient (in terms of processor and memory usage). HAProxy is used by a number of high-profile websites including GitHub, Bitbucket, Stack Overflow,Reddit, Tumblr, Twitterand , Tuentiand is used in the OpsWorks product from Amazon Web Services. This Image Provides Haproxy 1.6 with SSL support HAProxy is a free, very fast and reliable solution offering high availability, load balancing, and proxying for TCP and HTTP-based applications. It is particularly suited for very high traffic web sites and powers quite a number of the world’s most visited ones. Over the years it has become the de-facto standard opensource load balancer, is now shipped with most mainstream Linux distributions, and is often deployed by default in cloud platforms. Since it does not advertise itself, we only know it’s used when the admins report it. Haproxy is owned by Haproxy (http://www.haproxy.org/) and they own all related trademarks and IP rights for this software. Cognosys Provides Hardened images of Haproxy on the cloud ( AWS marketplace, Azure and Google Cloud Platform). Deploy Haproxy securely on cloud i.e. AWS marketplace, Azure and Google Cloud Platform (GCP)
Features
Basic features : Logging
Logging is an extremely important feature for a load balancer, first because aload balancer is often wrongly accused of causing the problems it reveals, and second because it is placed at a critical point in an infrastructure where all normal and abnormal activity needs to be analyzed and correlated with other components.HAProxy provides very detailed logs, with millisecond accuracy and the exact connection accept time that can be searched in firewalls logs (e.g. for NAT correlation). By default, TCP and HTTP logs are quite detailed an contain everything needed for troubleshooting, such as source IP address and port, frontend, backend, server, timers (request receipt duration, queue duration, connection setup time, response headers time, data transfer time), global process state, connection counts, queue status, retries count, detailed stickiness actions and disconnect reasons, header captures with a safe output encoding. It is then possible to extend or replace this format to include any sampled data, variables, captures, resulting in very detailed information. For example it is possible to log the number of cumulative requests or number ofdifferent URLs visited by a client.
The log level may be adjusted per request using standard ACLs, so it is possible to automatically silent some logs considered as pollution and instead raise warnings when some abnormal behavior happen for a small part of the traffic(e.g. too many URLs or HTTP errors for a source address). Administrative logs are also emitted with their own levels to inform about the loss or recovery of a server for example.Each frontend and backend may use multiple independent log outputs, which eases multi-tenancy. Logs are preferably sent over UDP, maybe JSON-encoded, and are truncated after a configurable line length in order to guarantee delivery.
Basic features : Statistics: HAProxy provides a web-based statistics reporting interface with authentication,security levels and scopes. It is thus possible to provide each hosted customerwith his own page showing only his own instances. This page can be located in a hidden URL part of the regular web site so that no new port needs to be opened.This page may also report the availability of other HAProxy nodes so that it is easy to spot if everything works as expected at a glance. The view is synthetic with a lot of details accessible (such as error causes, last access and last change duration, etc), which are also accessible as a CSV table that other tools may import to draw graphs. The page may self-refresh to be used as a monitoring page on a large display. In administration mode, the page also allows to change server state to ease maintenance operations.
Advanced features
. Advanced features : Management: HAProxy is designed to remain extremely stable and safe to manage in a regular production environment. It is provided as a single executable file which doesn’t require any installation process. Multiple versions can easily coexist, meaning that it’s possible (and recommended) to upgrade instances progressively by order of importance instead of migrating all of them at once. Configuration files are easily versioned. Configuration checking is done off-line so it doesn’t require to restart a service that will possibly fail. During configuration checks, a number of advanced mistakes may be detected (e.g. a rule hiding another one, or stickiness that will not work) and detailed warnings and configuration hints are proposed to fix them. Backwards configuration file compatibility goes very far away in time, with version 1.5 still fully supporting configurations for versions 1.1 written 13 years before, and 1.6 only dropping support for almost unused, obsolete keywords that can be done differently. The configuration and software upgrade mechanism is smooth and non disruptive in that it allows old and new processes to coexist on the system, each handling its own connections. System status, build options, and library compatibility are reported on startup. Some advanced features allow an application administrator to smoothly stop aserver, detect when there’s no activity on it anymore, then take it off-line,stop it, upgrade it and ensure it doesn’t take any traffic while being upgraded,then test it again through the normal path without opening it to the public, and all of this without touching HAProxy at all. This ensures that even complicated production operations may be done during opening hours with all technical resources available.
The process tries to save resources as much as possible, uses memory pools to save on allocation time and limit memory fragmentation, releases payload buffers as soon as their contents are sent, and supports enforcing strong memory limits above which connections have to wait for a buffer to become available instead of allocating more memory. This system helps guarantee memory usage in certain strict environments.
A command line interface (CLI) is available as a UNIX or TCP socket, to perform a number of operations and to retrieve troubleshooting information. Everything done on this socket doesn’t require a configuration change, so it is mostly used for temporary changes. Using this interface it is possible to change a server’s address, weight and status, to consult statistics and clear counters, dump and clear stickiness tables, possibly selectively by key criteria, dump and kill client-side and server-side connections, dump captured errors with a detailed analysis of the exact cause and location of the error, dump, add and remove entries from ACLs and maps, update TLS shared secrets, apply connection limits and rate limits on the fly to arbitrary frontends (useful in shared hosting environments), and disable a specific frontend to release a listening port (useful when daytime operations are forbidden and a fix is needed nonetheless).For environments where SNMP is mandatory, at least two agents exist, one is provided with the HAProxy sources and relies on the Net-SNMP Perl module. Another one is provided with the commercial packages and doesn’t require Perl.Both are roughly equivalent in terms of coverage.It is often recommended to install 4 utilities on the machine where HAProxy isdeployed : – socat (in order to connect to the CLI, though certain forks of netcat can also do it to some extents);- halog from the latest HAProxy version : this is the log analysis tool, it parses native TCP and HTTP logs extremely fast (1 to 2 GB per second) and extracts useful information and statistics such as requests per URL, per source address, URLs sorted by response time or error rate, termination codes etc. It was designed to be deployed on the production servers to help troubleshoot live issues so it has to be there ready to be used;
– tcpdump : this is highly recommended to take the network traces needed to troubleshoot an issue that was made visible in the logs. There is a moment where application and haproxy’s analysis will diverge and the network traces are the only way to say who’s right and who’s wrong. It’s also fairly commo to detect bugs in network stacks and hypervisors thanks to tcpdump;
– strace : it is tcpdump’s companion. It will report what HAProxy really sees and will help sort out the issues the operating system is responsible for from the ones HAProxy is responsible for. Strace is often requested when a bug in HAProxy is suspect
Advanced features : System-specific capabilities: Depending on the operating system HAProxy is deployed on, certain extra features may be available or needed. While it is supported on a number of platforms, HAProxy is primarily developed on Linux, which explains why some features are only available on this platform.The transparent bind and connect features, the support for binding connections to a specific network interface, as well as the ability to bind multiple processes to the same IP address and ports are only available on Linux and BSD systems, though only Linux performs a kernel-side load balancing of the incoming requests between the available processes.On Linux, there are also a number of extra features and optimizations including support for network namespaces (also known as “containers”) allowing HAProxy to be a gateway between all containers, the ability to set the MSS, Netfilter marks and IP TOS field on the client side connection, support for TCP FastOpen on the listening side, TCP user timeouts to let the kernel quickly kill connections when it detects the client has disappeared before the configured timeouts, TCP splicing to let the kernel forward data between the two sides of a connections thus avoiding multiple memory copies, the ability to enable the “defer-accept” bind option to only get notified of an incoming connection once data become available in the kernel buffers, and the ability to send the request with the ACK confirming a connect (sometimes called “piggy-back”) which is enabled with the “tcp-smart-connect” option. On Linux, HAProxy also takes great care of manipulating the TCP delayed ACKs to save as many packets as possible on the network.
Some systems have an unreliable clock which jumps back and forth in the past and in the future. This used to happen with some NUMA systems where multiple processors didn’t see the exact same time of day, and recently it became more common in virtualized environments where the virtual clock has no relation with the real clock, resulting in huge time jumps (sometimes up to 30 seconds have been observed). This causes a lot of trouble with respect to timeout enforcement in general. Due to this flaw of these systems, HAProxy maintains its own monotonic clock which is based on the system’s clock but where drift is measured and compensated for. This ensures that even with a very bad system clock, timers remain reasonably accurate and timeouts continue to work. Note that this problem affects all the software running on such systems and is not specific to HAProxy.The common effects are spurious timeouts or application freezes. Thus if this behavior is detected on a system, it must be fixed, regardless of the fact that HAProxy protects itself against it.
Advanced features : Scripting: HAProxy can be built with support for the Lua embedded language, which opens a wide area of new possibilities related to complex manipulation of requests or responses, routing decisions, statistics processing and so on. Using Lua it is even possible to establish parallel connections to other servers to exchange information. This way it becomes possible (though complex) to develop an authentication system for example. Please refer to the documentation in the file “doc/lua-api/index.rst” for more information on how to use Lua.
Sizing
Typical CPU usage figures show 15% of the processing time spent in HAProxy versus 85% in the kernel in TCP or HTTP close mode, and about 30% for HAProxy versus 70% for the kernel in HTTP keep-alive mode. This means that the operating system and its tuning have a strong impact on the global performance.Usages vary a lot between users, some focus on bandwidth, other ones on request rate, others on connection concurrency, others on SSL performance.
–Major Features of HAProxy : Load balancing
- Numerous balancing algorithms may be applied by server or by server group, with weighting
- Content switching: request routing based on their content
- SSL (one of the best SSL stack on the market)
- Multi criteria session persistence management
- HTTP header management via access control lists (ACL)
- Support web services and web sockets
High availability
- Smooth server shutdown and startup
- Overload protection
- Continuous server monitoring
- High availability (VRRP / Route Health Injection)
Application performance
- HTTP compression
- Management of server logs in offload mode
- Traffic analytic logs with customizable log format
- TCP/HTTP acceleration via buffering
- Dynamic connection control
- Early release of connections
- no limit in number of servers, farms, services (validated in production with 300.000 of each object)
Security
- Reverse-Proxy
- Protocol validation
- Information leaks prevention
- Protection against DoS, DDoS, worms, brute force, backdoor and Advanced persistent threat (APT)
- Real time behavior analysis
- Management of white/blacklists and URL restrictions
- Filtering of HTTP / HTTPS queries and replies
Integration and administration
- Protocol compliance
- full support of IPv6
- syslog
- proxy protocol (Amazon ELB, nginx, …)
- Integration with standard operating systems
- Backwards compatible with HAProxy configurations
Azure
Installation Instructions For Ubuntu
Note: How to find PublicDNS in Azure Step 1) SSH Connection: To connect to the deployed instance, Please follow Instructions to Connect to Ubuntu instance on Azure Cloud 1) Download Putty. 2) Connect to virtual machine using following SSH credentials : Host name: PublicDNS / IP of machine Port : 22 Username: Your chosen username when you created the machine ( For example: Azureuser) Password : Your Chosen Password when you created the machine ( How to reset the password if you do not remember) Step 2) Other Information: 1. Default configuration path: “/etc/haproxy/haproxy.cfg” 2. Default ports:
- Linux Machines: SSH Port – 22
Note: Open ports as required on cloud Firewall. Configure custom inbound and outbound rules using this link 3. To access Webmin interface for management please follow this link
Step by Step Screenshots :

Installation Instructions For Centos
Note: How to find PublicDNS in Azure Step 1) SSH Connection: To connect to the deployed instance, Please follow Instructions to Connect to Ubuntu instance on Azure Cloud 1) Download Putty. 2) Connect to virtual machine using following SSH credentials :
- Host name: PublicDNS / IP of machine
- Port : 22
Username: Your chosen username when you created the machine ( For example: Azureuser) Password : Your Chosen Password when you created the machine ( How to reset the password if you do not remember) Step 2) Other Information: 1.Default installation path: will be in your web root folder “/etc/haproxy/haproxy.cfg” 2.Default ports:
- Linux Machines: SSH Port – 22
Note: Open ports as required on cloud Firewall. Configure custom inbound and outbound rules using this link 3. To access Webmin interface for management please follow this link
Step by Step Screenshots :
- Installation Instructions For Windows
- Installation Instructions For Ubuntu
- Installation Instructions For Redhat
- Installation Instructions For CentOS
Installation Instructions For Windows
Step 1) VM Creation:
- Click the Launch on Compute Engine button to choose the hardware and network settings.

- You can see at this page, an overview of Cognosys Image as well as some estimated costs of VM.

- In the settings page, you can choose the number of CPUs and amount of RAM, the disk size and type etc.
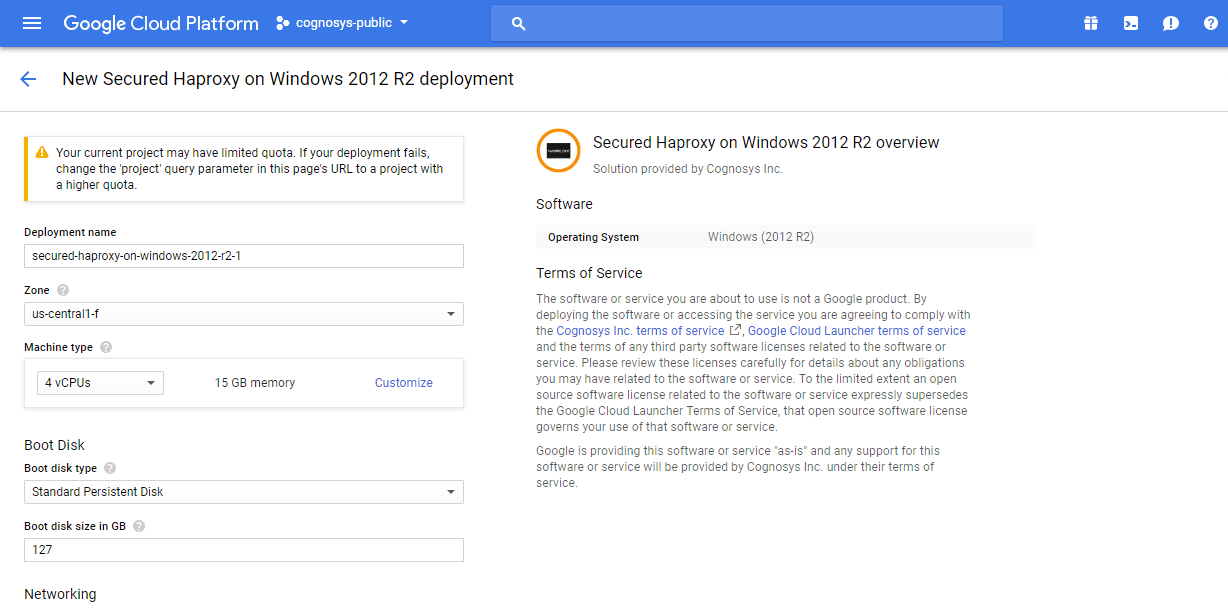

Step 2) RDP Connection: To initialize the DB Server connect to the deployed instance, Please follow Instructions to Connect to Windows instance on Google Cloud Step 3) Database Login Details: The below screen appears after successful deployment of the image. 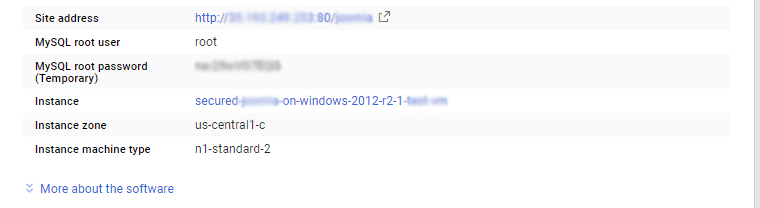 For local MySQL root password, please use the temporary password generated automatically during image creation as shown above. i) Please connect to Remote Desktop as given in step 2 to ensure stack is properly configured and DB is initialized. ii) You can use MySQL server instance as localhost, username root and password as shown above. If you have closed the deployment page you can also get the MySQL root password from VM Details “Custom metadata” Section
For local MySQL root password, please use the temporary password generated automatically during image creation as shown above. i) Please connect to Remote Desktop as given in step 2 to ensure stack is properly configured and DB is initialized. ii) You can use MySQL server instance as localhost, username root and password as shown above. If you have closed the deployment page you can also get the MySQL root password from VM Details “Custom metadata” Section
Installation Instructions For Ubuntu
Step 1) VM Creation:
- Click the Launch on Compute Engine button to choose the hardware and network settings.

- You can see at this page, an overview of Cognosys Image as well as some estimated costs of VM.

- In the settings page, you can choose the number of CPUs and amount of RAM, the disk size and type etc.

Step 2) SSH Connection: To connect to the deployed instance, Please follow Instructions to Connect to Ubuntu instance on Google Cloud 1) Download Putty. 2) Connect to the virtual machine using SSH key
- Hostname: PublicDNS / IP of machine
- Port : 22
Step 3) Other Information: 1.Default ports:
- Linux Machines: SSH Port – 22
2. To access Webmin interface for management please follow this link
Installation Instructions For Redhat
Step 1) VM Creation:
- Click the Launch on Compute Engine button to choose the hardware and network settings.
2.You can see at this page, an overview of Cognosys Image as well as some estimated costs of VM.
3.In the settings page, you can choose the number of CPUs and amount of RAM, the disk size and type etc.
Step 2) SSH Connection: To connect to the deployed instance, Please follow Instructions to Connect to Ubuntu instance on Google Cloud 1) Download Putty. 2) Connect to the virtual machine using SSH key
- Hostname: PublicDNS / IP of machine
- Port : 22
Step 3) Database Login Details: The below screen appears after successful deployment of the image. For local MySQL root password, please use the temporary password generated automatically during image creation as shown above. i) Please connect to Remote Desktop as given in step 2 to ensure stack is properly configured and DB is initialized. ii) You can use MySQL server instance as localhost, username root and password as shown above. If you have closed the deployment page you can also get the MySQL root password from VM Details “Custom metadata” Section Step 4) Application URL: Access the application via a browser at http://<yourip>/haproxy A) You will see the page where you can configure your site data with site name, haproxy admin name etc. B) On next page you will see configuration success message. C) You can login to the haproxy admin portal with the haproxy username and its generated password from point A shown above. D) You can access the configured site at http://yourIP/haproxy Step 5) Other Information: 1.Default ports:
- Linux Machines: SSH Port – 22
2. To access Webmin interface for management please follow this link
Installation Instructions For CentOS
Step 1) SSH Connection: To connect to the deployed instance, Please follow Instructions to Connect to CentOS instance on Google Cloud
1) Download Putty.
2) Connect to virtual machine using following SSH credentials:
- Hostname: PublicDNS / IP of machine
- Port : 22
Username: Your chosen username when you created the machine Password : Your Chosen Password when you created the machine ( How to reset the password if you do not remember)
Step 2) Other Information:
1.Default ports:
- Linux Machines: SSH Port – 22
2. To access Webmin interface for management please follow this link
AWS
Installation Instructions For CentOS
Installation Instructions For CentOS
Note: How to find PublicDNS in AWS
Step 1) SSH Connection: To connect to the deployed instance, Please follow Instructions to Connect to CentOS instance on AWS Cloud
1) Download Putty.
2) Connect to the virtual machine using SSH key Refer this link:
- Hostname: PublicDNS / IP of machine
- Port : 22
Videos
HAProxy Load Balancer
https://www.youtube.com/watch?v=Q8YueJNsNpo
How to set up loadbalancing on Ubuntu 14.04
HAproxy configuration and Load balancing
