1-click AWS Deployment 1-click Azure Deployment
Overview
SQL Integrity Check on cloud SQL Database integrity check the database integrity task contains checking the distribution and structural reliability of all the objects in the specified database.
Don’t assume that a backup will work, even if it passes RESTOREVERIFYONLY post backup. Only a restore and running CHECKDB verifies database validity. Over communicate with the end user and (or) client when this occurs. You want to be clear before this issue, during this issue, and while you’re correcting this issue.
You work in an environment with many SQL Servers that have several databases on each server, and one day you see that an integrity check failed on one of the databases. Let’s assume that nothing in the environment has been outlined, so you have no idea who the end user of this database is, or what priority level the data are. What are some things to keep in mind if this occurs, and ways to mitigate the confusion that may come when you have to make quick decisions?
Unfortunately, environments with many SQL Server instances running can overlook regular integrity checks and running DBCC CHECKDB is not an option if you want to prevent permanent data loss. If you aren’t currently running them, as that is the first problem that will need to be solved. Let’s look at a couple of data priority scenarios depending on importance that will be useful for the rest of this tip.
The Environment List
High Priority Databases
If databases hold data for an important business process that generates heavy revenue or could result in high costs due to loss, increase the frequency that you run an integrity check, even if that frequency is daily. In these environments, you cannot have a single point of failure, and when we’re talking high revenue or cost, one of the best approaches is an Active-Active environment, where one can be “taken down” for maintenance while the other is running and vice versa. The key in this environment is that any data loss is unacceptable, as any loss of data could be costly. Imagine a scenario of a company that stores bitcoin trades and it loses a trade of 10,000 bitcoins due to data corruption from a disk failure (one row of data loss – one row); do you think that the person who lost 10,000 bitcoins will be okay with, “Unfortunately, we lost some data after our integrity check failed” when this could have been prevented? No, and the company in that case should expect a lawsuit. Simply put: the business will understand the importance, if this scenario applies. In this scenario, the company cannot even lose one row of data without it potentially costing the company a massive amount of money.
Medium Priority Databases
If the databases hold data that are high priority, but a very small amount of data loss is acceptable – such as monthly payment information that is always the same amount based on a schedule – the business may accept losing a data value or two because it can be deduced, or because at worst, it means they will credit a customer with a payment, even if the customer did not make it. In these environments, to minimize data loss, run an integrity check before backing up the database, keep the databases in full recovery mode with frequent transaction log backups, and consider a set up like availability groups with AlwaysOn. In this scenario, we want to still lose as little data as possible in the worst case scenario, but we know that if we lose a small amount of data, the cost will be in a range that our business can accept.
Low Priority Databases
These databases hold low priority and data loss is acceptable. This may be data from an ETL process that can be re-loaded with a minimal time window, data that are stored on paper that have been saved to a database and can be re-loaded. A great example of this is data for marketing to new clients where a database stores potential clients: in some companies, these data could be re-loaded through the same process that identified these clients; for other companies, this may be a high or medium priority. The recovery plan for these is often a re-load, or in some cases, accepting data loss. In these environments, more than likely restoring an old backup, or using repair and accepting data loss will be acceptable. Make sure that you confirm this with the end user (or users) and never assume this without evidence.
The “Scary” Others
One disaster-waiting-to-happen when you are first introduced to an environment is a business team treating a database as less important than it is, as we always want to err on the side of caution; being overly cautious is less of a problem in most cases. In an ideal environment, you will know how important each database is for each server before ever experiencing an integrity check failure; however, this will seldom occur and often, it will be an after-the-fact discovery. As an example, you may view a database as on the low priority list based on how its designed or discussed, only to find out later that it’s a high priority database where no data loss is acceptable. Likewise, you may propose a solution to immediately move the database to an architecture where there is no single point of failure due to its priority, yet the business procrastinates on this. In some situations, you may want to quickly exit the company or contract with the client as the disaster will be on you even if you warned about the disaster that could happen.
The Solutions
High Priority Databases
In the case of high priority databases in large environments (or environments in which the revenue model is in the billions), I refuse to accept a design that is not Active-Active and clients or companies can find another DBA and (or) Architect if they won’t support this model. A company that makes a billion dollars from a database can pay the costs to run at least two active instances where reports or processes can be pointed to the currently active one. This also makes required maintenance – like checking integrity – easy since I can run maintenance on one while the other is the database the application uses, then flip the switch when I’m ready to run maintenance on the other.
I’ve seen a few instances and heard of many more where a manual failover was required in the Always On model and the application experienced data loss from failure entering the application; I like Always On for medium priority databases or a behind-the-scenes support of one Active node in an Active-Active model, but when we’re talking at least 9 figures in revenue, it’s too great of risk to run it. In the case of an Active-Active model, I’ve never run into a situation where both nodes had corrupt databases, though relative to the hardware there is a probability of this happening. When we’re talking about high priority databases, we are dealing with a situation where even one record being lost is too much and the only way to eliminate, or significantly reduce, that risk is architecture designed for it.
In general, architecture, appropriate maintenance tasks and regular disaster recovery drills centered around database corruption to support recovery are required for any low, medium or high priority environment. When designing a model in the beginning large environments, always document your suggestions with the pros and cons of any approach (including your own), along with your concerns. Because none of us have an infinite amount of time, I would highly suggest delineating a limit on support if a team chooses to go a route without consideration of the support required, otherwise you may find yourself supporting a model you recommended against.
Medium Priority Databases
In the case of medium priority databases, I will try to some techniques to first see if I can pass CHECKDB without any data loss. These include, but are not limited to:
- Restoring a database with most recent logs and verifying CHECKDB on another server. The key here is to pin-point the failure window.
- Drop all the non-clustered indexes and re-create them (relative to the CHECKDB error). I’ve been blessed in my career that this has fixed most of the issues, relative to the error output from CHECKDB.
- Relative to the error and the output of checking integrity on the table level, dropping a table and re-creating it from the backup and restore, if the table is a look-up table where values haven’t been added (or won’t be).
Do these techniques always fix the issue? No. In the worst of situations, losing data may occur and I convey what is lost. Because these are medium priority databases, going into the situation, I know that a small amount of data loss are acceptable and post restore with the transaction logs, I fill in what’s needed, such as amortization payments that may have been missing, but are deduced.
Low Priority Databases
In the case of low priority databases, I will use some of the methods above in the medium priority category – like re-creating non-clustered indexes – but I know that data loss is allowed and there’s a trade off in time if I spend days correcting a database in an environment where we have thousands of databases, and data loss is allowed for the low priority database.
A few other very important points about experiencing this issue:
- Don’t keep your backups in only one location. Expect to lose at least one location or run into corrupted backups from time to time.
- Create a regular restore schedule for your backups – this is much easier in an Active-Active environment but applies to medium priority environments too. Don’t assume that a backup will work, even if it passes RESTOREVERIFYONLY post backup. Only a restore and running CHECKDB verifies database validity.
- Over communicate with the end user and (or) client when this occurs. You want to be clear before this issue, during this issue, and while you’re correcting this issue. Communication builds trust.
Other Things to Consider
Finally, I’ve observed a strong correlation between log micro-management and CHECKDB failures in my experience. I dislike log micro-management, but many environments engage in this and it’s an unfortunate reality; the best practice is pre-setting log growth, adjusting the database to simple or full recovery, relative to needs, and teaching developers to batch their processes instead of loading entire data sets. My preference for logs has always been what I call the High-Low-Middle model after the famous pool game: generally, logs should be pre-sized according to configuration set in this model. As data volume grow, this is something developers should know in general. In the case of simple recovery models, I’ll force developers to work around the error of ACTIVE_TRANSACTION, while in full recovery models, I’ll make sure the log is backing up frequently (still, transactions should be run in smaller batches). There’s absolutely no reason to try and add a petabyte of data in one transaction. If you’re in an environment with log micro-management, in my experience, CHECKDB failures are only a matter of time.
SQL Database integrity check
The database integrity task contains checking the distribution and structural reliability of all the objects in the specified database. It can contain checking the database indexes.It’s a good practice to run database integrity check on a set schedule, however there are some occasions when you will need to run check in some other times eg after hardware failure, electrical surge, the server unexpected shut down.SQL Server provides number of commands to check the logical and physical integrity of all the objects in the specified database.
Data Integrity is used to maintain accuracy and consistency of data in a table.
Declarative Ease
Define integrity constraints using SQL statements. When you define or alter a table, no additional programming is required. The SQL statements are easy to write and eliminate programming errors. Oracle controls their functionality. For these reasons, declarative integrity constraints are preferable to application code and database triggers. The declarative approach is also better than using stored procedures, because the stored procedure solution to data integrity controls data access, but integrity constraints do not eliminate the flexibility of ad hoc data access.
Centralized Rules
Integrity constraints are defined for tables (not an application) and are stored in the data dictionary. Any data entered by any application must adhere to the same integrity constraints associated with the table. By moving business rules from application code to centralized integrity constraints, the tables of a database are guaranteed to contain valid data, no matter which database application manipulates the information. Stored procedures cannot provide the same advantage of centralized rules stored with a table. Database triggers can provide this benefit, but the complexity of implementation is far greater than the declarative approach used for integrity constraints.
Maximum Application Development Productivity
If a business rule enforced by an integrity constraint changes, then the administrator need only change that integrity constraint and all applications automatically adhere to the modified constraint. In contrast, if the business rule were enforced by the code of each database application, developers would have to modify all application source code and recompile, debug, and test the modified applications.
Immediate User Feedback
Oracle stores specific information about each integrity constraint in the data dictionary. You can design database applications to use this information to provide immediate user feedback about integrity constraint violations, even before Oracle runs and checks the SQL statement. For example, an Oracle Forms application can use integrity constraint definitions stored in the data dictionary to check for violations as values are entered into the fields of a form, even before the application issues a statement.
Superior Performance
The semantics of integrity constraint declarations are clearly defined, and performance optimizations are implemented for each specific declarative rule. The Oracle optimizer can use declarations to learn more about data to improve overall query performance. (Also, taking integrity rules out of application code and database triggers guarantees that checks are only made when necessary.)
Flexibility for Data Loads and Identification of Integrity Violations
You can disable integrity constraints temporarily so that large amounts of data can be loaded without the overhead of constraint checking. When the data load is complete, you can easily enable the integrity constraints, and you can automatically report any new rows that violate integrity constraints to a separate exceptions table.
The Performance Cost of Integrity Constraints
The advantages of enforcing data integrity rules come with some loss in performance. In general, the cost of including an integrity constraint is, at most, the same as executing a SQL statement that evaluates the constraint.
Types of Integrity Constraints
You can use the following integrity constraints to impose restrictions on the input of column values:
NOT NULL Integrity Constraints
UNIQUE Key Integrity Constraints
PRIMARY KEY Integrity Constraints
Referential Integrity Constraints
CHECK Integrity Constraints
Data Integrity is used to maintain accuracy and consistency of data in a table.
Classification of Data Integrity
1. System/Pre Defined Integrity
2. User-Defined Integrity

System/Pre Defined Integrity:

We can implement this using constraints. This is divided into three categories.
Entity Integrity
Entity integrity ensures each row in a table is a uniquely identifiable entity. We can apply Entity integrity to the Table by specifying a primary key, unique key, and not null.
Referential Integrity
Referential integrity ensures the relationship between the Tables.
We can apply this using a Foreign Key constraint.
Domain Integrity
Domain integrity ensures the data values in a database follow defined rules for values, range, and format. A database can enforce these rules using Check and Default constraints.
Constraints
Constraints are used for enforcing, validating, or restricting data.
Constraints are used to restrict data in a Table.
Constraints in SQL Server
Default
Default Constraint is used to assign the default value to the particular column in the Table.
By using this constraint we can avoid the system-defined value from a column while the user inserts values in the Table.
A Table can contain any number of default constraints.
Default constraints can be applied on any datatypes.
Example
1. Create table Demo(Id int,name varchar(50),Salary int default 15000)
Unique
Unique constraints are used to avoid duplicate data in a column but accept null values in the column.
It also applies to any datatypes.
A Table can contain any number of unique constraints.
1. Create table demo1(id int unique,name varchar(50),price int unique)
Not Null
It avoids null values from column-accepted duplicate values.
It can apply on any datatype.
A Table can contain any number of not null constraints.
Example
1. Create table Demo2(id int not null, age int)
Important Points to Remember
Unique and Not Null constraints have their own disadvantage, that is accepting null and duplicate values into the Table. So to overcome the above drawbacks we write the combination of Unique and Not Null on a column.
Example
Create table demo 3
Check
It is used to verify or check the values with the user-defined conditions on a column.
It can apply on any datatypes.
A Table can contain any number of Not Null constraints.
Example
1. Create table demo4(id int, Age int check(Age between 18 and 24))
Primary key
Primary key adds features of unique and not null constraints.
By using primary key we can avoid duplicate and null values for the column.
It can apply on any datatype like int, char, etc.
A table can contain one primary key only.
Example
1. Create table demo5(id int primary key, salary money)
Composite primary key
If a primary key is created on multiple columns the composite key can apply to a maximum of 16 columns in a table.
Example
1. create table demo6(id int,name varchar(50),primary key(id,name))
Important points to remember,
1. We can apply only a single primary key in a Table.
2. We can apply the primary key constraint on multiple columns in a Table.
3. The primary key is also called the composite key and candidate key.
Foreign Key
Most important part of the database is to create the relationship between the database Table.
The relationship provides a method for link data stored in two or more Tables so that we can retrieve data in an efficient way and verify the dependency of one table data in other Table.
Important Rules to Create Foreign Key constraint
In order to create a relation between multiple tables, we must specify a Foreign key in a Table that references a column in another Table which is the primary key column.
We require two tables for binding with each other and those two tables have a common column name and those columns should be the same datatype.
• If a table contains a primary key then it can be called parent Table.
• If a Table contains a foreign key reference then it can be called a Child Table.
We can apply the foreign key reference on any datatypes.
By default foreign key accepts duplicate and null values.
We can apply a maximum of 253 foreign keys on a single table.
Example
Step 1
1. Create table employee(id int primary key,name varchar(50),age int)
Step 2
1. Create table company(email varchar(50),address varchar(50),id int primary key foreign references employee(id))
Now, check the relation between the two tables. Click the database name, click database diagrams, click on new database diagrams, and select table employee and company and see the relation between these tables.

If we want to delete or update the record in the foreign key child table then we need to follow some rules.
For delete
It is used to delete key values in the parent table which is referenced by the foreign key in other tables. All rows that contain those foreign key in child table are deleted.
For Update
It is used to update a key value in the parent table which is referenced by the foreign key in another table. All rows that contain the foreign keys in the child table are also updated.
Using the Foreign key we can maintain three types of relationships,
1. One to one
2. One to many
3. Many to many
One to one
A row in a Table associated with a row in the other Table is known as one to one relationship.
One to many or many to one
A row in a Table associated with any number of rows in the other Table is known as a one-to-many relationship.
Many to many relationship
Many rows in a table are associated with many rows in the other Table. This is called a many to many relationship
Simple Steps to Check the Integrity of SQL Server Database
There are often errors and bugs encountered in MS SQL Server 2000, 2005, 2008, 2008 R2, 2012, 2014 and 2016. The first step to recovering corrupt database files is to run an integrity check. These are a set of commands that perform checks on the MDF and LDF files. It returns a list of errors and provides a proper course of recovery. This post describes all the ways on how to check the consistency of database. It explains all the steps necessary in repairing databases based on their priority level. According to which, measures can be undertaken to resolve the issue and restore database files and corresponding data.
Reasons to Check Integrity of SQL Server Database
Following are some of the problems that may lead an administrator to check integrity of SQL Server database and consistency:
• One of the servers has issues or bugs in an environment with multiple SQL servers.
• Potential inconsistencies between the database and server primary and log files.
• Run DBCC CheckDB on database to check all logical and physical integrity of all objects in the specific database.
• Remove any data corruption causing cause all sorts of issues within the database.
• Frequently failed SQL statements, incorrect results or SQL instance not working.
Disadvantages of Running DBCC CheckDB Command
There are instances where the integrity check on the complete database may prove disadvantageous. Here is why:
Time Consuming: It takes hours to completely check each and every logic of MS SQL Server.
Data Integrity Not Ensured: Running DBCC CheckDB Command may change some important data that may cause more problems than usual.
Not a Well-Defined Way: It is not recommended to run a check a complete database without proper plan or backups.
Difficult to Identify Errors: The DBCC CheckDB command returns a list of hundreds of errors. It is difficult to pinpoint the exact error location and fix it.
SQL Server Database Consistency Check
Instead of applying a fix to the entire database, the SQL Server recovery can be done by breaking down databases based on priority. Following are the different priority level and ways to recover data.
Solution#1 High Priority Databases
These are databases that hold important company data which can incur MS SQL Server consistency issues. Any corruption in this database can create heavy revenue losses and millions in damages. This environment cannot have a single point of failure or it may lead to lawsuits and legal actions.
Here are the major steps in order to check SQL Server database consistency in high priority databases:
• Use an Active-Active environment for database management.
• Then, taken down one server for maintenance and keep other running,
• Run integrity check on a frequent basis, almost daily.
• Before building large environment by self, consider all pros and cons.
• Take careful considerations and precautions while building a new model.
• Consult support team on every level and choose a route accordingly.
Solution#2 Medium Priority Databases
These contain information like monthly payment information. Some data loss is fairly acceptable in such a case. Customers can be reimbursed based on the technical glitch on the company’s part. The cost inured is within acceptable parameters to the company and no class action will be taken. So, follow the steps below on how to check the integrity of SQL Server with medium priority databases:
• Run an integrity check before taking and backups
• Keep the databases in full recovery mode.
• Take frequent backups of complete database and transaction logs.
• Set up Availability groups that are AlwaysOn.
• Now, check database integrity using DBCC CheckDB.
• Restore from the most recent backup log in case of command failure.
• Check the error log and drop the corresponding non-clustered indexes and recreate them.
• If the error is in a complete table, drop the table and recreate it from a backup.
Solution#3 Low Priority Databases
In these cases, data loss is completely acceptable. These are usually marketing or employee records that are stored on paper or in some digital manner. Information can be easily reloaded in case of data loss after running DBCC CheckDB command. Here are the ways to dealing with this situation:
• Apply Repair_Allow_Data_Loss as a course of action suggested by the integrity check.
• Restore database from an old backup.
• Also, confirm with the customer and notify them about the information update.
• Keep multiple copies of backups in different locations.
• Create a regular restore schedule for your backups.
Solution#4 Use an Expert Solution
There is a more direct approach to recover database after DBCC consistency check. It is simple yet effective third-party tool that makes the entire task more professional and easier. It is the SQL Repair that can repair and recover all SQL Server database without data loss. It is one of the best tools in the market to scan and recover multiple MDF and LDF files in one go. The manual solutions provide an easy fix to all database issues. It is highly recommended that all organizations, big or small take regular backups and run DBCC check.
Solution for SQL Server Database Integrity Checks
In order to check SQL Server database integrity problem, database administrator executes the DBCC (database console commands) statements. You may or may not have heard about this command but it is used to perform the operation like Maintenance, Miscellaneous, Informational, and Validation. However, for checking the logical or physical integrity of the SQL Server database, it is required to run DBCC CHECKDB command.
There are following operations that are performed by using the CHECKDB command:
- DBCC CHECKALLOC– It checks the consistency of disk storage structure for a particular database.
- DBCC CHECKTABLE – This command is used to check the SQL Server database integrity of all the pages & structures that manage the view of table or index.
- DBCC CHECKCATALOG – It executes to check the consistency within the particular database.
- DBCC CHECKDB – This is used to check the catalog consistency in the specified SQL database.
Syntax of DBCC CHECKDB

What is the Objective of the DBCC CHECKDB?
There are mainly two roles of DBCC CHECKDB command. The first objective is to check SQL Server database Integrity and the second is to correct the errors.
Integrity Check:
The DBCC CHECKDB command follows a few steps on its execution for SQL Server database Integrity checks.
- Verify the allocated structures such as GAM, SGAM, PFS, IAM
- Verify the table consistency and its all indexes.
- Finally, verify all the system catalogs.
Correction:
Once you have checked the SQL database and noticed that integrity has not been maintained. Then, you need to correct all the possible damaged or distorted pages. The DBCC CheckDB itself can fix these damages.
The “REPAIR_ALLOW_DATA_LOSS” option changes the corrupted page for a new one. By using this command, you can save the integrity of the SQL Server database. But, you should keep in mind, we are only talking about the physical structure, not about the internal data integrity.
Another option to correct the SQL Server database integrity is “REPAIR_REBUILD” command. It is used to correct the problem in non clustered indexes. With the help of this option, we do not lose the data items.
Process to Execute CHECKDB Command
If talking about the process to execute the CHECKDB command, it does not directly run on the SQL database. For running the command, it creates a hidden database snapshot and the command runs based on this snapshot. But, most of the people realize this only when CheckDB command denies executing and once they start searching on it, they find out about “some snapshot” that failed the creation. In this situation, you will definitely want to what to do if the snapshot creation fails? There are three options for this. You can choose any of these:
- Fix the permission to create the hidden snapshot.
- Execute the DBCC CHECKDB with the TABLOCK option. This can bring problems, as the database will be a target of locks.
- Create a process by following these steps:
- Create a snapshot of the database.
- Run the DBCC CheckDB command on this snapshot.
Limitations of SQL Server Database Integrity Checks Command
Even though, DBCC CHECKDB command maintains the SQL Server Database integrity, there are few limitations like it will not able to repair the major issues in SQL database integrity. Also, system tables and data purity detected errors cannot be resolved by using DBCC CHECKDB command. SQL database should be on SINGLE_USER mode to perform the correction by using DBCC CHECKDB command.
When CHECKDB Command Does Not Work?
If DBCC CHECKDB failed to maintain the Microsoft SQL Server database integrity check, you can use the SQL Database Recovery Tool as an alternate option. This software has the facility to maintain both internal and external integrity after performing the recovery process. It scans your database and find out the issue and recover it simultaneously. Apart from this, there are several features provided by this professional tool which makes it different from others.
Bringing It All Together
SQL database plays an important role for any organization. There are many reasons that can affect the SQL Server database integrity, so you must check SQL Server database integrity on the database. Hence, we have discussed DBCC CHECKDB command to perform SQL Server database integrity checks whether it is maintained or not. If it does not maintain, the command will correct the issues. But, in the case of a major problem, it is advised to use SysTools SQL Database Recovery software.
Frequently Asked Questions
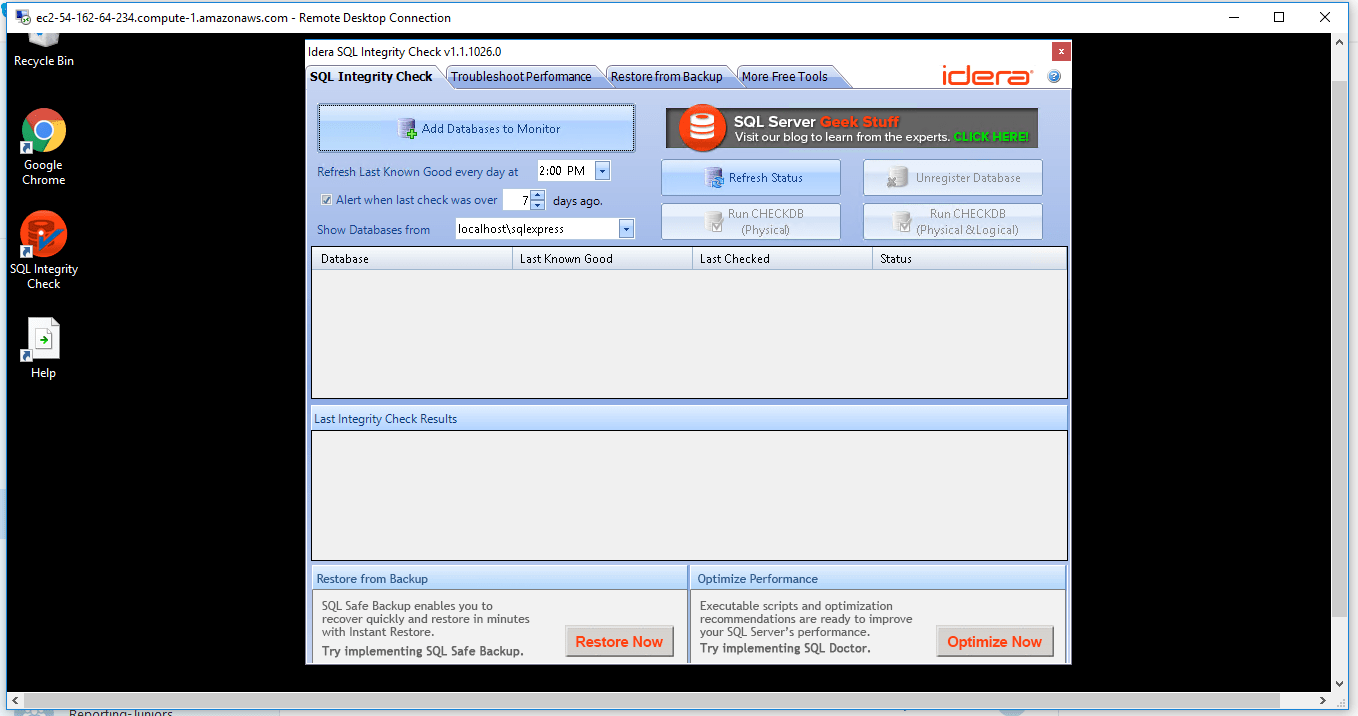
SQL Integrity Check, the latest free tool from Idera, allows DBAs to skip the time-consuming task of writing and maintaining T-SQL scripts to find SQL Server database corruption issues. Now DBAs can leverage the easy-to-use SQL Integrity Check interface to continuously monitor SQL databases. Additional features include:
- Initiate Integrity Checks—Easily run a CHECKDB integrity check for any database, on-demand
- Identify Corruption—View integrity check results to identify database corruption
- Verify Last Integrity Check—Track date of last successful integrity check
- Automatic Notifications—Receive timely reminders to run integrity checks
SQL Integrity Check on cloud For AWS

Features
Major Features of SQL Integrity Check
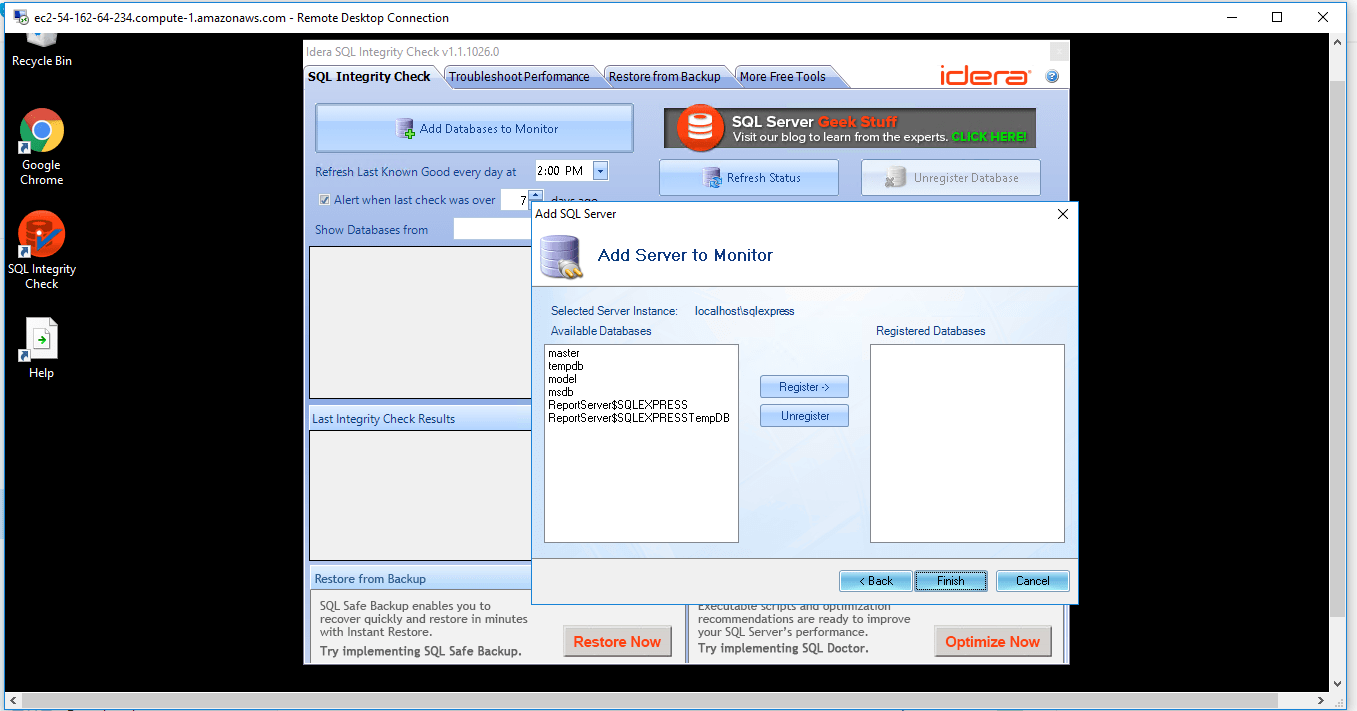
Verify Last Integrity Check : Register databases and SQL Integrity Check will, on a regular basis, verify when the last known successful integrity check was performed. This helps identify any possible corruption early on so you can take action quickly instead of finding out a fix is needed after the corruption has grown even larger in scope.
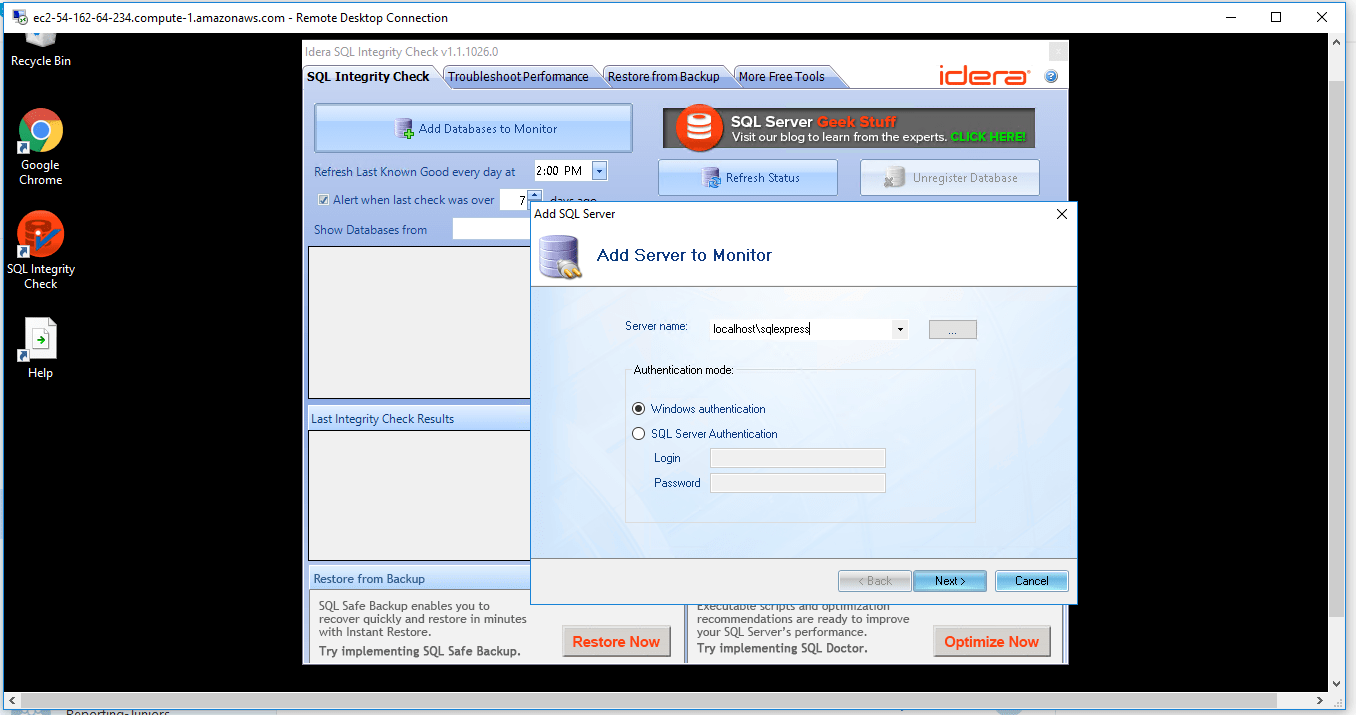
Initiate Integrity Checks : Run a CHECKDB integrity check anytime on-demand for any SQL server. No need to write any t-sql, just open the tool and select the SQL server.
Identify Database Corruption : After an integrity check is complete, SQL Integrity Check will present the errors and corruption areas discovered in a very easy-to-understand report along with the recommended repair level. You can then determine what remedial actions are needed to fix the errors.
Automatic Notification : Set frequency levels for how often you would like to perform integrity checks. Plus receive notification automatically via the system tray when those dates have been exceeded. This ensures that you are regularly checking the integrity of your SQL Server databases.
Save Time : There is no need to write or maintain any t-sql scripts to run integrity checks. SQL Integrity Check will run checks for you on any of the SQL Servers you have registered to track.
AWS
Installation Instructions For Windows
A) Click the Windows “Start” button and select “All Programs” and then point to SQL Integrity Check
B) RDP Connection: To connect to the operating system,
1) Connect to virtual machine using following RDP credentials :
- Hostname: PublicDNS / IP of machine
- Port : 3389
Username: To connect to the operating system, use RDP and the username is Administrator.
Password : Please Click here to know how to get password .
C) Other Information:
1.Default installation path: will be on your root folder “C:\Program Files (x86)\Idera\SQL Integrity Check\”
2.Default ports:
- Windows Machines: RDP Port – 3389
- Http: 80
- Https: 443
Configure custom inbound and outbound rules using this link
Users Instructions Screenshots